


Python asyncio tutorial: 3 real-world examples
Learn how to write concurrent code in Python using the async/await syntax.


Apify is all about making the web more programmable. Our SDK for Python is a great toolkit to help simplify the process of making scrapers. This tutorial aims to give you a solid understanding of handling multiple tasks simultaneously with Python.
Handling multiple tasks at the same time can greatly enhance an application's performance. This is the principle behind asynchronous programming, allowing tasks to operate side-by-side. So, even if one task is on hold, others can keep going. While this approach is efficient, Python doesn't support it natively. But why does this matter?
Imagine needing to fetch data from several websites. Traditional Python coding would handle one site at a time, waiting for each to finish before moving to the next. This method can be time-consuming. With asynchronous programming, these fetches can happen simultaneously and thereby boost code performance.
To address this, the asyncio module was introduced to bring asynchronous capabilities to the Python ecosystem. It provides the tools and libraries we need to write concurrent code using the async/await syntax.
In this tutorial, we'll explore how to use asyncio to our advantage in real-world scenarios. But first, let’s take a quick look at why asyncio was introduced to Python and what features it brought to the table.
Understanding Python's asyncio
Asyncio wasn't always part of Python. Introduced in Python 3.4 and refined in subsequent versions, it was a response to the growing need for handling I/O-bound operations more efficiently.
To better understand asyncio let’s take a look at some of its core concepts, coroutines, event loops, tasks, and async/await syntax.
Coroutines
In Python, coroutines are an evolved form of generators. While generators can produce values on-demand and pause at each “yield”, coroutines go a step further by both consuming and producing values through “yield” and “await”.
Specifically, within the asyncio framework, the async def syntax defines a coroutine function. However, invoking this function doesn't execute it instantly. Instead, it yields a coroutine object. Inside this function, the await keyword pauses its process until the awaited action finishes, all without halting the entire event loop.
The primary benefit of this approach is non-blocking IO operations. For instance, when making a network request, the program doesn't get held up waiting for a response. The coroutine simply pauses, allowing other tasks to proceed. Once the response arrives, the coroutine picks up from where it paused.
For example, take a look at the code sample below showcasing how we can create a coroutine using async def:
import asyncio
async def fetch_data():
# Simulate a network delay with asyncio.sleep
await asyncio.sleep(2)
return "data fetched"
As highlighted earlier, simply invoking a coroutine function, such as fetch_data(), doesn't initiate its execution. Instead, it returns a coroutine object like <coroutine object fetch_data at 0x7f20228348c0>.
To properly run a coroutine, we should use the asyncio.run() function:
result = asyncio.run(fetch_data())
print(result) # Outputs: data fetched
Event loop
In asyncio an event loop manages and distributes the execution of different tasks in a Python program, ensuring they run seamlessly without blocking the main thread.
Essentially, when a coroutine is paused using an await expression, the event loop detects this and switches to executing another task. Once the awaited task is complete, the event loop resumes the paused coroutine. This mechanism is what facilitates the concurrent execution of tasks, making asynchronous programming so effective. Here's a simple example:
import asyncio
async def task_one():
await asyncio.sleep(1)
print("Task one complete")
async def task_two():
await asyncio.sleep(2)
print("Task two complete")
# Create an event loop
loop = asyncio.get_event_loop()
# Run tasks using the event loop
loop.run_until_complete(asyncio.gather(task_one(), task_two()))
# Close the loop
loop.close()
In this example, the event loop runs both task_one and task_two concurrently. Though task_one completes first due to a shorter sleep time, the event loop ensures that both tasks operate without causing the other to wait unnecessarily.
Tasks
Building upon our discussion about coroutines and event loops, we arrive at the concept of "tasks" in asyncio.
A task is a way to schedule the execution of coroutines concurrently. In essence, a task is a coroutine wrapped by the event loop, enabling it to run as a separate unit within the loop, thus maximizing the concurrent execution of multiple operations.
The primary significance of tasks is their ability to initiate coroutines and let the event loop manage their completion while also allowing for potential cancellations or checking on their statuses.
For example, consider you have two coroutines that you wish to run. Instead of waiting for one to complete before starting the other, you can convert both into tasks and let the event loop handle their concurrent execution:
import asyncio
async def coroutine_one():
await asyncio.sleep(2)
print("Coroutine one finished")
async def coroutine_two():
await asyncio.sleep(1)
print("Coroutine two finished")
async def main():
# Convert coroutines to tasks
task1 = asyncio.create_task(coroutine_one())
task2 = asyncio.create_task(coroutine_two())
# The event loop will now handle both tasks concurrently
await task1
await task2
# Run the main coroutine
asyncio.run(main())
In the provided code, coroutine_two will finish before coroutine_one, despite being started later. This is the essence of tasks. They allow the event loop to execute multiple coroutines effectively, streamlining the process and ensuring efficient use of resources.
As you can see, each of these concepts closely interacts with the other, building the foundation of the asyncio framework.
Async/Await
Finally, it's time to take a closer look at async/await. As you may have noticed, these keywords were frequently used in our previous examples. But what is their significance in the realm of asynchronous programming?
The async keyword is utilized to declare an asynchronous function, which - when called - doesn't execute immediately but instead returns a coroutine object. This coroutine object is then typically run by an event loop.
The await keyword, on the other hand, is used within these async functions. It essentially signals Python to pause the execution of the current function, allowing other tasks to run until the awaited operation completes. This is where the asynchronous magic happens; by "awaiting" I/O-bound operations (like our prior examples of network requests or sleeping tasks), we ensure that the event loop remains unblocked, enabling concurrent execution.
Getting started with asyncio development
Now it's time to see how asyncio fares in real-world scenarios. But before we get our hands dirty with coding, let's ensure our development environment is primed and ready.
Python version
It's essential to be running Python 3.7 or a more recent version. Over the years, Python's asynchronous capabilities have seen significant improvements. Utilizing the newer versions ensures that you have access to the most up-to-date features and can benefit from optimal performance.
Initialize a Python virtual environment
Despite not being a required step, it's considered good practice to use a virtual environment to ensure a clean and isolated workspace for our project.
This helps separate the dependencies specific to our project from our system's global Python environment. To set up a virtual environment within the project directory of your choice, execute the following command:
python -m venv venv
Once the virtual environment is created, you'll need to activate it:
- For Windows:
venv\\Scripts\\activate
- For macOS and Linux:
source venv/bin/activate
By activating the virtual environment, any Python packages we install will be confined to this environment, ensuring a consistent and conflict-free setup.
Installing necessary libraries
The upcoming examples will leverage a few external libraries to showcase the full power of asyncio. So, make sure you've installed these libraries before following along with the code examples in this article:
pip install aiohttp fastapi beautifulsoup4
aiohttp: An asynchronous HTTP client/server framework. We'll be using this for tasks such as web scraping and making asynchronous API requests.
FastAPI: This is an asynchronous web framework tailored for crafting speedy APIs with Python. It combines performance with ease of use, making it a popular choice in the Python async world.
BeautifulSoup: A library for parsing HTML and XML documents. BeautifulSoup (BS4) is incredibly popular in the Python ecosystem, so chances are you are that you are already somewhat familiar with it. BS4 offers mechanisms for us to navigate and search through parsed data structures and is commonly utilized for web scraping tasks in conjunction with other libraries.
Finally, we will also need an ASGI server for production, such as Uvicorn. You can install it by running the command below:
pip install "uvicorn[standard]"
Example 1: asynchronous web scraper
Web scraping is a technique employed to extract large amounts of data from websites. When dealing with multiple pages or sites, it can be time-consuming to fetch each page sequentially, and here's where asynchronous programming can prove useful.
Why use async for web scraping?
In traditional scraping, we'd fetch a page, process it, and then move to the next. If a page takes 2 seconds to load, scraping 100 pages sequentially would take at least 200 seconds. But with async, we can initiate multiple fetches concurrently, significantly reducing our total scraping time.
To highlight the benefits of asynchronous web scraping, we'll create two versions of the same web scraper: one synchronous and its asynchronous counterpart. We'll then conduct a performance test to compare their efficiency.
Synchronous web scraper
In the code below, we have a synchronous web scraper using BeautifulSoup and Requests. This scraper will fetch the URL, Title, and Rank of each article from the initial four pages of the HackerNews website and create a JSON file containing the scraped data.
👉 The goal of this article is not to do a deep dive into writing web scrapers. But if you're interested in the topic and would like to learn more, check out our What are the best Python web scraping libraries? post, where we test some of the most popular scraping tools in the Python ecosystem. Or, have a read of this comprehensive guide on web scraping with Python.
import requests
from bs4 import BeautifulSoup
import json
# Fetch the content of a URL using the requests library
def fetch_url(url):
response = requests.get(url)
return response.text
# Extract relevant data from an individual article element
def extract_data_from_article(article):
url_elem = article.find(class_="titleline")
rank_elem = article.find(class_="rank")
return {
"URL": url_elem.find("a").get('href'),
"title": url_elem.getText(),
"rank": rank_elem.getText().replace(".", "")
}
# Parse the page content and return extracted data from all articles
def extract_articles_from_page(page_content):
soup = BeautifulSoup(page_content, 'html.parser')
articles = soup.find_all(class_="athing")
return [extract_data_from_article(article) for article in articles]
# Main function to fetch all URLs and extract the article data
def main():
urls = ['https://news.ycombinator.com/news?p=1', 'https://news.ycombinator.com/news?p=2', 'https://news.ycombinator.com/news?p=3', 'https://news.ycombinator.com/news?p=4']
# Fetch all page contents using requests
pages = [fetch_url(url) for url in urls]
# Extract articles from each fetched page and aggregate them
all_articles = [article for page in pages for article in extract_articles_from_page(page)]
# Save extracted data to a JSON file
with open('sync_scraped_data.json', 'w', encoding='utf-8') as file:
json.dump(all_articles, file, ensure_ascii=False, indent=4)
if __name__ == "__main__":
main()
Asynchronous web scraper
Now it’s time to build the async version of our web scraper. To do that, let's walk through the steps we need to take to modify our previous synchronous code and make it asynchronous:
Replace the
Requestslibrary withaiohttp.aiohttpis built on top ofasyncioand offers non-blocking socket operations, which is just what we need for concurrent fetching.Modify the function definitions to use the
asynckeyword, which means they'll now return coroutine objects. Whenever you're making an HTTP request or doing any other IO-bound operation, use theawaitkeyword to ensure non-blocking behavior.Instead of fetching each page one by one, we'll initiate multiple fetches using
asyncio.gather(). This function can run multiple coroutines concurrently.Instead of just calling
main(), we'll useasyncio.run(main())to execute the asynchronous main function.
💡 While BeautifulSoup itself isn't asynchronous, parsing HTML content isn't typically the bottleneck. So, we'll continue to use BeautifulSoup in the same way as the synchronous version to extract data.
import aiohttp
import asyncio
from bs4 import BeautifulSoup
import json
# Fetch the content of a URL using aiohttp asynchronously
async def fetch_url(session, url):
async with session.get(url) as response:
return await response.text()
# Extract relevant data from an individual article element
def extract_data_from_article(article):
url_elem = article.find(class_="titleline")
rank_elem = article.find(class_="rank")
return {
"URL": url_elem.find("a").get('href'),
"title": url_elem.getText(),
"rank": rank_elem.getText().replace(".", "")
}
# Parse the page content and return extracted data from all articles
async def extract_articles_from_page(page_content):
soup = BeautifulSoup(page_content, 'html.parser')
articles = soup.find_all(class_="athing")
return [extract_data_from_article(article) for article in articles]
# Main function to fetch all URLs and extract the article data
async def main():
urls = ['https://news.ycombinator.com/news?p=1', 'https://news.ycombinator.com/news?p=2', 'https://news.ycombinator.com/news?p=3', 'https://news.ycombinator.com/news?p=4']
# Create aiohttp session and fetch all page contents
async with aiohttp.ClientSession() as session:
tasks = [fetch_url(session, url) for url in urls]
pages = await asyncio.gather(*tasks)
# Extract articles from each fetched page and aggregate them
all_articles = [article for page in pages for article in await extract_articles_from_page(page)]
# Save extracted data to a JSON file
with open('async_scraped_data.json', 'w', encoding='utf-8') as file:
json.dump(all_articles, file, ensure_ascii=False, indent=4)
if __name__ == "__main__":
asyncio.run(main())
Benchmark - sync vs. async web scraper performance
Okay, now that we have both versions of our scraper ready, it's time to put them to the test and see if and how much more performant asynchronous programming can make our code.
To run this benchmark, we'll use the hyperfine command-line benchmarking tool. All we have to do is run the command below and then wait a few seconds for Hyperfine to display the results in the terminal.
hyperfine "python3 sync.py" "python3 async.py" --warmup=3
Result:

Sync vs. async web scraper benchmark results
From the benchmark results, we can see that the asynchronous version (async.py) of the code ran approximately 3.41 times faster than its synchronous counterpart (sync.py). This means the asynchronous version finished its tasks in roughly 29.33% (or 1/3.41) of the time it took the synchronous version.
To put it into perspective, the asynchronous version of our code was 241% more performant than the synchronous one. That’s a really impressive number, especially when you consider the potential business impact of this performance boost in a real-world application.
Example 2: async API server
API servers often deal with multiple requests simultaneously. Whether it's fetching data from databases, interacting with other services, or processing information, there are many instances where the server is waiting. This means that using asynchronous operations can help maximize the throughput of our server.
Traditional servers vs. async servers
In a conventional server setup, when a request is made, the server processes that request and often waits for data to be retrieved, potentially blocking subsequent requests. This setup can reduce the efficiency of handling multiple incoming requests. On the other hand, an asynchronous server can manage other requests while waiting for data from a previous one, optimizing its overall efficiency.
Building an async API server with FastAPI
FastAPI is a popular framework for building APIs in Python. Due to its support of asynchronous operations, FastAPI is handy for creating async APIs quickly.
So, let’s go over an example to demonstrate what an async API would look like:
from fastapi import FastAPI
import asyncio
app = FastAPI()
@app.get("/")
async def read_root():
await asyncio.sleep(1) # Simulating a delay
return {"Hello": "World"}
Asynchronous server
To run the server, save the above code to a file (e.g, main.py) and then run the command:
uvicorn main:app --reload
And that’s it. Our asynchronous server is now up and running. Easy, right?
While there's nothing fancy going on in this example, it will be enough for us to demonstrate how performant and asynchronous a server can be when compared to its synchronous counterpart.
Benchmark - sync vs. async server performance
To perform this test, we'll use wrk, a popular HTTP benchmarking tool. Let’s start by stress-testing our asynchronous server with the following command:
wrk -t12 -c400 -d15s http://127.0.0.1:8000/
This runs a benchmark for 15 seconds, using 12 threads and keeping 400 HTTP connections open.
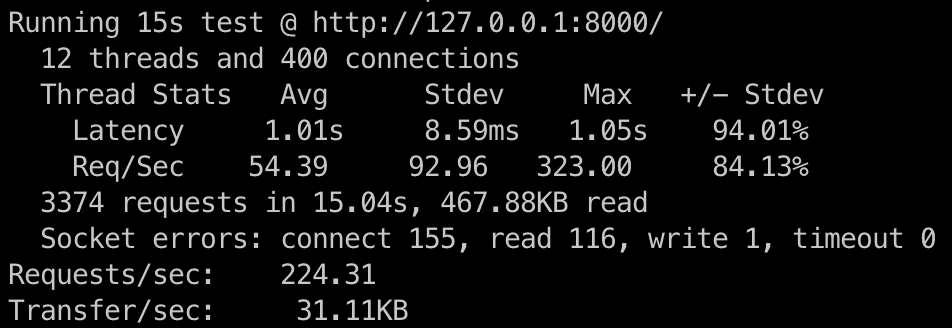
Async server benchmark results
With the results for our asynchronous server in hand, let’s test its synchronous counterpart. But first, we need to adapt the code to make it synchronous.
For the synchronous counterpart using FastAPI, we'll basically remove the async and await keywords, and instead of using asyncio.sleep, we can use time.sleep:
from fastapi import FastAPI
import time
app = FastAPI()
@app.get("/")
def read_root():
time.sleep(1) # Simulating a delay, e.g., fetching data or processing
return {"Hello": "World"}
Synchronous server
Running the same benchmark for the synchronous server, we got this:
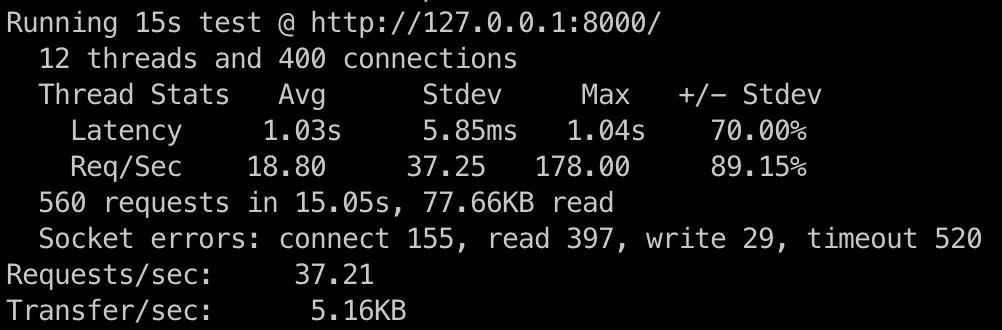
Sync server benchmark results
Great. So now let’s do a quick analysis of the results:
The asynchronous server processed 224.31 requests per second, whereas the synchronous server managed 37.21 requests per second. This indicates the asynchronous server is about 6 times faster than its synchronous counterpart.
When using the synchronous server's performance as a reference (100%), the asynchronous server performs at roughly 600%. This equates to a 500% increase in performance over the synchronous server. Quite impressive, considering how few changes there were to our code, right?
Example 3: asynchronous database operations
When building applications, especially web apps, interactions with databases are frequent. Whether reading, writing, or updating data, these operations can sometimes be a bottleneck, especially if we deal with substantial data or have multiple users accessing the system concurrently.
Async databases: a quick rundown
Typically, when we query a database, our application waits for the results before it continues. If we're fetching a large dataset, this waiting time can add up. An async database setup, on the other hand, allows our application to work on other tasks while it's waiting for the database.
Setting up a MySQL database
Before we jump into the code, we first need to set up a simple test database to interact with. Let’s do that.
1. Install MySQL server
On Ubuntu/Debian:
sudo apt update
sudo apt install mysql-server
On CentOS/Red Hat:
sudo yum install mysql-server
sudo systemctl start mysqld
On Windows:
For Windows, you'd typically download the MySQL installer from the official MySQL website and then follow the installation instructions in the graphical user interface. There isn't a direct command-line equivalent to apt or yum for MySQL installation on Windows.
On macOS (using Homebrew):
brew install mysql
brew services start mysql
2. Secure MySQL installation (recommended)
After installation, it's a good practice to run the following:
sudo mysql_secure_installation
This script will guide you through a series of prompts where you can set a root password, remove anonymous users, disable remote root login, etc.
3. Login to MySQL
mysql -u root -p
You will be prompted for the root password you just set (or set previously).
4. Create the database and user
While in the MySQL shell, execute:
CREATE DATABASE testdb;
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON testdb.* TO 'username'@'localhost';
FLUSH PRIVILEGES;
EXIT;
5. Create a table and a sample column
USE testdb;
CREATE TABLE some_table (some_column INT);
INSERT INTO some_table (some_column) VALUES (1), (2), (3), (4), (5);
And that’s it. Now leave your newly created database running, and let’s write some code.
Asynchronous database operations with aiomysql
aiomysql is a library for accessing a MySQL database from Python's asyncio. We haven’t installed this library yet, so let’s do it now:
pip install aiomysql
Next, let's dive into the code:
import asyncio
import aiomysql
# Asynchronously retrieve data from the database
async def get_data(pool):
# Acquire a connection from the connection pool
async with pool.acquire() as conn:
# Create a cursor object to interact with the database
async with conn.cursor() as cur:
# Execute a SQL query to fetch some data
await cur.execute("SELECT some_column FROM some_table;")
# Print all the fetched data
print(await cur.fetchall())
async def main():
# Create a connection pool to the database
pool = await aiomysql.create_pool(host='127.0.0.1', port=3306,
user='username', password='password',
db='testdb')
# Schedule tasks to get data concurrently
tasks = [get_data(pool) for _ in range(10)]
await asyncio.gather(*tasks)
# Close the connection pool after all tasks are completed
pool.close()
await pool.wait_closed()
if __name__ == "__main__":
asyncio.run(main())
Okay, so what's happening here?
We're creating a connection pool to the MySQL database using
aiomysql.create_pool.get_datafunction fetches data from the database. We use connection pooling to manage and reuse database connections efficiently.In
main, we create multiple tasks to fetch data concurrently usingasyncio.gather.
In summary, asynchronous databases let us handle multiple database operations concurrently. This improves the application's speed and performance. Concurrent operations result in efficient task processing and faster responses, which, in turn, can improve both the user experience and the system's efficiency.
That’s a wrap!
Throughout this tutorial, we explored a few real-world scenarios where asynchronous programming could prove useful and significantly boost our applications’ performance. So, for the sake of a quick recap, here's how async programming impacts each of the three examples we went through:
Web scraping: Speeding up data extraction from multiple pages or sites.
API servers: Maximizing server throughput and improving response times.
Database operations: Enhancing data access and operations in data-centric applications.
The bottom line? Asynchronous programming lets us manage multiple operations simultaneously without waiting for one to finish before starting the next, which can be a handy way of improving performance in certain applications.
However, it's essential to identify an application's primary bottlenecks to determine the best optimization methods. Asynchronous programming is one tool among many for enhancing performance. As applications grow in complexity, various strategies can be employed to boost their efficiency.