


Python tuple vs. list
Learn the differences between Python lists and tuples and when and how to use them.


Hey, we're Apify. You can build, deploy, share, and monitor your Python web scrapers on the Apify platform. Check us out.
A brief intro to lists and tuples
Lists and tuples are the most versatile and useful data types for storing data in Python. Lists and tuples share many similarities. For example, both can store items of various data types, allow for duplicates, and permit access to items via their index.
But for all their similarities, tuples and lists also have some differences and their unique use cases. Each one is best suited for different scenarios. To understand the distinctions between them, it's important to be aware of some important factors, such as mutability, memory usage, performance, and hashing. We'll go through those factors in this tutorial.
Definition and syntax
Lists and tuples are built-in heterogeneous and sequential data types in Python. By heterogeneous, we mean they can store any kind of data type. These data types allow you to store an ordered collection of one or more items. By 'ordered', we mean that the order in which you put the elements is kept the same.
Python lists
Lists are dynamic in nature, so you can easily add or remove items at any time. As a list is mutable, you can easily change and modify the list elements. However, it can't be used as the key in a dictionary.
A list is created using the square brackets ([]). Below, we've created different types of lists. Some lists contain only integers, while others contain only strings. There are also mixed lists that contain both integers and strings and nested lists that have other lists.
integer_list = [1, 2, 3, 4, 5]
alphabet_list = ["a", "b", "c", "d", "e"]
combined_list = ["a", 1, "b", 2, "c", 3, "4"]
nested_list = [1, 2, 3, [4, 5, 6], 7, 8]
print(integer_list)
print(alphabet_list)
print(combined_list)
print(nested_list)
Python provides the type() method, which you can use to identify the type of an object, such as whether it's a list, tuple, or any other data type. For example, in the above code, we created a couple of lists. If we pass them to the type()method, the output would be <class 'list'>.
integer_list = [1, 2, 3, 4, 5]
print(type(integer_list)) # Output: <class 'list'>
You can also use the list() function to create a list from any iterable object, such as a string, tuple, or set.
# Create a list from a string
lst = list("abc")
print(lst) # ['a', 'b', 'c']
# Create a list from a tuple
lst = list((1, 2, 3))
print(lst) # [1, 2, 3]
# Create a list from the set
lst = list({"a", "b", "c"})
print(lst) # ['c', 'a', 'b']
Now, let's discuss some basic operations that can be performed on list elements.
The elements in a list can be accessed using an index. List indexing is zero-based, which means the index starts at 0.
Consider the following list:
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
The indices for the list will be:

Now access some elements of the list (lst) via their index:
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[0]) # Output: Apify
print(lst[3]) # Output: Proxy
Also, you can access their elements via negative indices. The negative index starts at the end of the list.

lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[-1]) # CLI
print(lst[-3]) # Actors
Slicing
Slicing is used to select a range of elements from a list. The colon (:) operator is used to create a slice of a list.
The syntax looks like this:
lst[start:stop:step]
start is the index where the slicing starts. The default is 0.
stop is the index where the slicing ends (excluding the value of this index). The default is the length of the array.
step is the step of the slicing. The default is 1.
When you slice without specifying the start or end index, you get a complete copy of the list.
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[:]) # ['Apify', 'Crawlee', 'Actors', 'Proxy', 'CLI']
To slice a list from a specific start index to the end of the list, here's what you can do:
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[1:]) # ['Crawlee', 'Actors', 'Proxy', 'CLI']
print(lst[2:]) # ['Actors', 'Proxy', 'CLI']
By passing indices 1 and 2 as the start index, the slicing would start from these start indices to the end of the list.
To slice a list up to a specific end index without specifying the start index, do this:
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[:2]) # ['Apify', 'Crawlee']
print(lst[:4]) # ['Apify', 'Crawlee', 'Actors', 'Proxy']
Here, the slicing starts at 0 (as it's not specified) and continues until the index you have specified, such as index 2 and 4. The end index won't be included, so the slice will occur before the end index.
To slice a list from a specific starting and ending point, do this:
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[1:4]) # ['Crawlee', 'Actors', 'Proxy']
print(lst[2:5]) # ['Actors', 'Proxy', 'CLI']
Here, 1:4 will slice from index 1 to 3 and will not include index 4. Similarly, for 2:5.
Now, let's look at slicing using step.
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[1:4:2]) # ['Crawlee', 'Proxy']
Here, the slicing starts from index 1 and ends at index 4 with a step of 2. The above output shows that first, the value at index 1 is printed, then it steps by 2, so it becomes index 3, and the value at index 3 is printed.
Similarly, you can perform slicing using negative indices.
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[-4:-2]) # ['Crawlee', 'Actors']
print(lst[1:-1]) # ['Crawlee', 'Actors', 'Proxy']
print(lst[-2:]) # ['Proxy', 'CLI']
To reverse the elements of the list, you can use [::-1].
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
print(lst[::-1]) # ['CLI', 'Proxy', 'Actors', 'Crawlee', 'Apify']
Add elements using the append() method and remove elements using the remove() method. When using the remove()method, you have to pass the element itself, not its index.
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
lst.append("Scraping")
print(lst) # ['Apify', 'Crawlee', 'Actors', 'Proxy', 'CLI', 'Scraping']
lst.remove("Crawlee")
print(lst) # ['Apify', 'Actors', 'Proxy', 'CLI', 'Scraping']
To remove an element using the index, you have to use the del keyword. As shown below, the element at index 2 will be deleted from the list.
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
del lst[2] # remove element via index
print(lst) # ['Apify', 'Crawlee', 'Proxy', 'CLI']
Python tuples
Tuples are similar to lists in all aspects except for the following: Tuples are immutable and defined by enclosing the elements in parentheses (()). You can't change the value of the tuple once you have created it. As a tuple is immutable, it can be used as a key in a dictionary.
Here's a simple example of creating different kinds of tuples:
integer_tuple = (1, 2, 3, 4, 5)
alphabet_tuple = ("a", "b", "c", "d", "e")
combined_tuple = ("a", 1, "b", 2, "c", 3, "4")
nested_tuple = (1, 2, 3, (4, 5, 6), 7, 8)
print(integer_tuple)
print(alphabet_tuple)
print(combined_tuple)
print(nested_tuple)
Similar to the list, you can use the type() function to identify the type of an object. For example, in the above code, we created a couple of tuples. If we pass them to the type() function, the output would be <class 'tuple'>.
integer_tuple = (1, 2, 3, 4, 5)
print(type(integer_tuple)) # <class 'tuple'>
When creating a tuple with a single item, don't forget to add a comma at the end. This comma tells Python that the object is a tuple, even though it may seem confusing at first. If you don't add the comma, Python will interpret the object as a simple expression, such as an integer or string.
tup = (21,)
print(type(tup)) # <class 'tuple'>
tup = (21)
print(type(tup)) # # <class 'int'>
As you can see, a tuple with a comma is interpreted as a tuple, while a tuple without a comma is interpreted as an integer.
You can use the tuple() function to create a tuple from an iterable object such as a list, string, or set.
# Create a tuple from a string
tup = tuple("abc")
print(tup) # ('a', 'b', 'c')
# Create a tuple from a list
tup = tuple([1, 2, 3])
print(tup) # (1, 2, 3)
# Create a tuple from the set
tup = tuple({"a", "b", "c"})
print(tup) # ('c', 'a', 'b')
You can access the elements easily via the index. The index could be positive or negative. Here's a simple example.
tup = ("Apify", "Crawlee", "Actors", "Proxy", "CLI")
print(tup[2]) # Actors
print(tup[-2]) # Proxy
Slicing is similar to lists. Just mention the start, step, or stop points properly.
tup = ("Apify", "Crawlee", "Actors", "Proxy", "CLI")
print(tup[1:3]) # ('Crawlee', 'Actors')
print(tup[1:4:2]) # ('Crawlee', 'Proxy')
print(tup[:3]) # ('Apify', 'Crawlee', 'Actors')
print(tup[3:]) # ('Proxy', 'CLI')
print(tup[-4:-2]) # ('Crawlee', 'Actors')
Similarly to a list, you can reverse the tuple elements using [::-1].
tup = ("Apify", "Crawlee", "Actors", "Proxy", "CLI")
print(tup[::-1]) # ('CLI', 'Proxy', 'Actors', 'Crawlee', 'Apify')
Note: Unlike a list, a tuple can't be modified. You’ll learn about the immutability of a tuple in the next section.Mutability vs. immutability
The main difference between a list and a tuple is that lists are mutable, while tuples are immutable. What does this mean? You can change the values of a list after it has been created, but you can't change the values of a tuple.
You can't use a list as a key in a dictionary because lists are mutable. However, you can use tuples as keys in a dictionary.
Other than tuples, Python provides a number of built-in immutable data types, such as numerical types (int, float, and complex) and collection types (str and bytes). Apart from lists, mutable built-in data types are dictionaries and sets.
Here are a few examples that show how lists are mutable:
The list of elements will be updated if you try to change the elements at specific indexes. As shown in the code below, the elements at index 2 and index -2 are updated.
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
lst[2] = "Scraping"
lst[-2] = "Store"
print(lst) # ['Apify', 'Crawlee', 'Scraping', 'Store', 'CLI']
What if you want to change multiple contiguous elements in a list at once? You can do this by using slice assignment. Since lists are mutable, contiguous elements can be easily changed, as shown in the code below.
lst = ["Apify", "Crawlee", "Actors", "Proxy", "CLI"]
lst[2:5] = ["Scraping", "Store"]
print(lst) # ['Apify', 'Crawlee', 'Scraping', 'Store']
Let's look at the pros and cons of mutable objects:
Pros of mutable objects
Mutable objects can be modified in place, which avoids the need to create new objects. This can be more efficient.
They are easier to work with when you need to add, remove, or modify elements.
Cons of mutable objects
Mutable objects cannot be used as keys in a dictionary or as elements in a set.
Mutable objects can be more challenging to debug and are more prone to errors, as their state can change unexpectedly. This can lead to unexpected side effects, especially in concurrent or multithreaded environments.
Now, let's dive into the immutable nature of tuples.
Below is an example that shows how tuples are immutable.
tup = ("Apify", "Crawlee", "Actors", "Proxy", "CLI")
tup[2] = ["Scraping"]
print(tup)
The result is this:
Traceback (most recent call last):
File "c:\\Users\\triposat\\test.py", line 2, in <module>
tup[2] = ['Scraping']
TypeError: 'tuple' object does not support item assignment
In the code above, we’re trying to change the element at index 2, but we fail to do so. This is because tuples, being immutable, can't be changed after they've been created.
Let's look at the pros and cons of immutable objects:
Pros of immutable objects
Immutable objects can be used as keys in a dictionary and as elements in a set because their values don't change.
They're less prone to errors when used in concurrent or multithreaded environments because they can't be modified.
Cons of immutable objects
If you need to change the value of an immutable object, you must create a new one, which can be less efficient. Frequent creation of new objects can impact performance in certain scenarios.
Immutable data types can take up more memory because you need to create a new object each time you change the data.
Common list and tuple methods
There are various common methods for lists and tuples that are generally used while performing various common tasks. Let's take a look at the common methods for both lists and tuples separately, with examples of each.
List methods
The list has some common methods that are used widely, such as append, remove, pop, insert, etc.
- Append: Adds an item to the end of the list.
lst = [1, 2, 3]
lst.append(4)
print(lst) # [1, 2, 3, 4]
- Extend: Appends all the elements of the iterable (e.g., another list) to the end of the list.
lst = [1, 2, 3]
lst.extend([4, 5])
print(lst) # [1, 2, 3, 4, 5]
- Insert: Inserts an element at the specific index in the list.
lst = [1, 4, 5]
lst.insert(1, 3)
print(lst) # [1, 3, 4, 5]
- Remove: Removes the first occurrence of the specified element from the list.
lst = [1, 4, 4, 5]
lst.remove(4)
print(lst) # [1, 4, 5]
- Pop: Removes the element at the specified index. Pop also returns the item of this specified index.
lst = [1, 2, 3, 4]
item = lst.pop(1)
print(item) # 2
print(lst) # [1, 3, 4]
- Index: Returns the index of the first occurrence of the specified element.
lst = [1, 3, 3, 4]
ind = lst.index(3)
print(find) # 1
- Count: Returns the number of times a specific item appears in a list.
lst = [1, 3, 3, 4]
cnt = lst.count(3)
print(cnt) # 2
Tuple methods
Tuples have fewer methods compared to lists because tuples are immutable.
- Count: Returns the number of times an element occurs in the tuple.
tup = (1, 3, 3, 4)
cnt = tup.count(3)
print(cnt) # 2
- Index: Returns the index of the first occurrence of the specified item in the tuple.
tup = (1, 3, 3, 4)
ind = tup.index(3)
print(ind) # 1
List and tuple methods
There are also various other common methods that you can use to perform operations on lists and tuples. Here are a few of them:
- Reversed: Reverses the order of elements. We’re using the tuple and list methods in the code because the
reversedmethod returns an iterator object (<reversed object at 0x0000024F8C0FB190>). Therefore, to convert it to a specific data type, you can use either method.
tup1 = (1, 2, 3)
lst = [1, 2, 3]
print(tuple(reversed(tup1))) # (3, 2, 1)
print(list(reversed(lst))) # [3, 2, 1]
- Sorted: Sorts the element in ascending order.
tup1 = (3, 2, 1)
lst = [3, 2, 1]
print(sorted(tup1)) # [1, 2, 3]
print(sorted(lst)) # [1, 2, 3]
- Concatenation: Concatenates two or more data types to create a data type.
tup1 = (1, 2)
tup2 = (3, 4)
tup = tup1 + tup2
print(tup) # (1, 2, 3, 4)
lst1 = [1, 2]
lst2 = [3, 4]
lst = lst1 + lst2
print(lst) # [1, 2, 3, 4]
Similarly, you can use the len(), min(), and max() functions for both lists and tuples.
Performance considerations
Lists allocate more bit buckets than the actual memory required due to the dynamic nature of lists. This is done to prevent the costly reallocation operation that happens in case additional items are added in the future. On the other hand, tuples are immutable data types that don't require extra space to store new objects.
Internally, both lists and tuples are implemented as arrays of pointers to the items. When you remove an item, the reference to that item gets destroyed. This removed item can still be alive if there are other references in your program to it.
Allocation
A tuple is a fundamental data type and is used a lot internally. You may not notice it, but you’re using tuples in various scenarios, such as:
When returning two or more items from a function.
Iterating over dictionary key-value pairs.
Working with arguments (*args) and parameters.
A running program typically has thousands of allocated tuples.
import gc
def type_stats(type_obj):
objects = gc.get_objects()
count = sum(1 for obj in objects if type(obj) == type_obj)
return count
print(type_stats(tuple)) # 390
print(type_stats(list)) # 72
Similarly, as you write more code, the number of tuples will increase. Here's an example that shows how the number of tuples increases when we create a dictionary.
import gc
def type_stats(type_obj):
objects = gc.get_objects()
count = sum(1 for obj in objects if type(obj) == type_obj)
return count
hashMap = {"Apify": 1, "Crawlee": 2}
print(type_stats(tuple)) # 391
print(type_stats(list)) # 72
The code below shows that the number of tuples suddenly increases after importing the random module compared to lists. This shows that tuples are used extensively internally.
import gc
def type_stats(type_obj):
objects = gc.get_objects()
count = sum(1 for obj in objects if type(obj) == type_obj)
return count
import random
print(type_stats(tuple)) # 532
print(type_stats(list)) # 74
Copies vs. reused
Because tuples are immutable, they don't need to be copied. In contrast, lists require all the data to be copied to create a new list. Therefore, tuples will perform better than lists in this scenario.
a = ("Apify", "Crawlee", "CLI")
b = tuple(a)
print(id(a)) # 1982517203904
print(id(b)) # 1982517203904
print(a is b) # True
a = ["Apify", "Crawlee", "CLI"]
b = list(a)
print(id(a)) # 1982515591552
print(id(b)) # 1982518764160
print(a is b) # False
Over-allocate
Since a tuple's size is fixed, it can be stored more compactly than lists, which need to over-allocate to make append()operations efficient. This provides tuples with a significant space advantage.
import sys
print(sys.getsizeof(tuple(iter(range(100))))) # 840
print(sys.getsizeof(list(iter(range(100))))) # 1000
Note: Here's what lists do to make append() operations efficient (from the official Objects/listobject.c file):This over-allocates proportional to the list size, making room for additional growth. The over-allocation is mild, but it is enough to give linear-time amortized behavior over a long sequence of appends() in the presence of a poorly performing system realloc().
Speed
You might expect the tuple to be slightly faster. Let's test it for some cases. Open your Jupyter Notebook and type the following command. Here, we’re using timeit, which measures the execution time of small code snippets.
from timeit import timeit
timeit("(1, 2, 'Apify', 'Crawlee')", number=10_000_000) # 0.14382770000000278
from timeit import timeit
timeit("[1, 2, 'Apify', 'Crawlee']", number=10_000_000) # 0.9290422999999919
from timeit import timeit
timeit("(1, 2, ['Apify', 'Crawlee'])", number=10_000_000) # 1.2866319000000033
To understand the above code more clearly, look at the compilation process.
from dis import dis
dis(compile("(1, 2, 'Apify', 'Crawlee')", "String", "eval"))
Here’s the code output:

It loaded the tuple as a constant and returned the value. It took one step to compile. This is called constant folding.
from dis import dis
dis(compile("[1, 2, 'Apify', 'Crawlee']", "String", "eval"))
Here’s the code output:

When compiling a list with the same elements, the compiler will first load each individual constant, then build the list and return it.
from dis import dis
dis(compile("(1, 2, ['Apify', 'Crawlee'])", "String", "eval"))
Here’s the code output:

In the third example, we used a tuple that contains a list. Similarly, it’ll first load all the constants, then build a list, then a tuple, and finally return it.
Great! Now, let's compare the speed of retrieving elements from lists and tuples.
from timeit import timeit
tup = tuple(range(1_000_000))
lst = list(range(1_000_000))
timeit('tup[999_999]', globals=globals(), number=10_000_000)
timeit('lst[999_999]', globals=globals(), number=10_000_000)
Run the timeit methods one by one, and you’ll see that tuples are slightly faster than lists at retrieving elements.
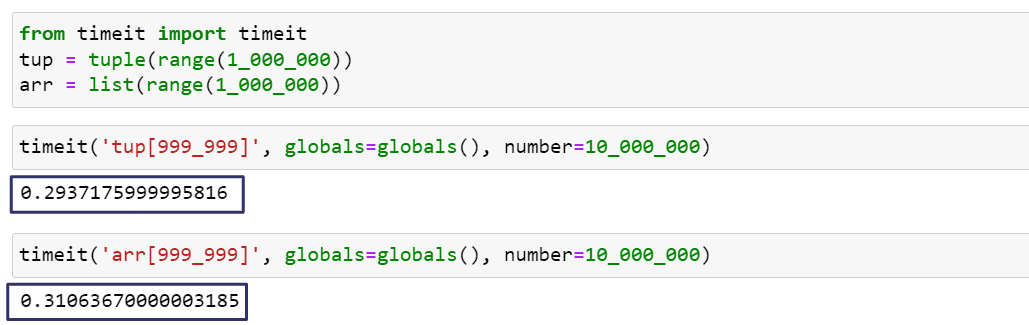
Tuples appear to be slightly faster than lists because, in CPython, tuples have direct access to their elements, while lists need first to access a separate array that contains pointers to the elements of the list.
Allocation optimization for tuples and lists
To speed up memory allocation and reduce memory fragmentation for tuples and lists, Python reuses old tuples and lists. This means that if you create a tuple or list and then delete it, Python does not actually delete it permanently. Instead, it moves it to a free list.
For tuple:

For list:

x and y have the same ID because they both point to the same object in memory, which is a previously destroyed tuple or list that was on the free list.
Advanced features
You may be familiar with some common methods for both lists and tuples. However, there's also a variety of advanced features that can be used to perform tasks more efficiently. Some of these features include empty lists and tuples concept, tuple packing and unpacking, list resizing, and more.
Empty tuple vs. empty list
When creating an empty tuple, Python points to the preallocated memory block, which saves a lot of memory. This is possible because tuples are immutable.
x = ()
y = ()
print(id(x)) # 2255130656832
print(id(y)) # 2255130656832
print(x is y) # True
That's amazing! However, it's not possible to do this with a list because it's mutable.
x = []
y = []
print(x is y) # False
print(id(x)) # 2103107729792
print(id(y)) # 2103107736512
List resizing
To avoid the cost of resizing, Python doesn't resize a list every time you need to add or remove an item. Instead, each list has a hidden buffer of empty slots that can be used to store new items. If the buffer is full, Python allocates additional space for the list. The number of slots in the buffer is based on the current size of the list.
The official documentation describes it as follows:
*This over-allocates proportional to the list size, making room for additional growth. The over-allocation is mild but is enough to give linear-time amortized behavior over a long sequence of appends() in the presence of a poorly-performing system realloc().
The growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...*
See the pictorial representation for memory allocation in the list:
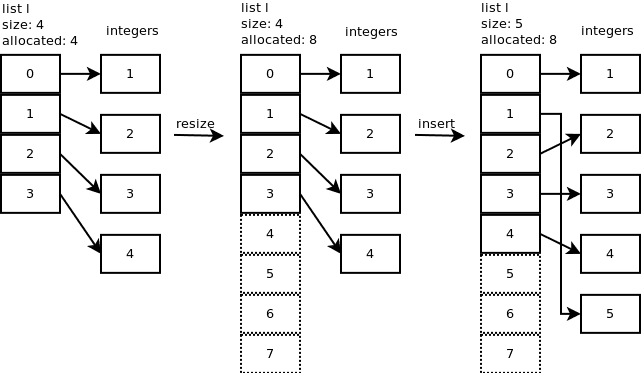
https://www.laurentluce.com/posts/python-list-implementation/
Tuple unpacking
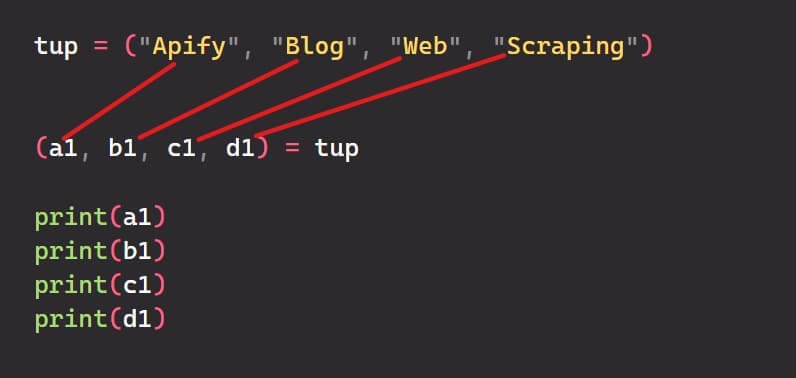
Assigning the elements of a tuple to multiple variables is a convenient way to extract values from the tuple.
tup = ("Apify", "Blog", "Web", "Scraping")
(a1, b1, c1, d1) = tup # or you can use: a1, b1, c1, d1 = tup
print(a1) # Apify
print(b1) # Blog
print(c1) # Web
print(d1) # Scraping
Look at the below image:
Packing and unpacking can be combined into a single statement to make it clearer.
(a1, b1, c1, d1) = ("Apify", "Blog", "Web", "Scraping")
print(a1) # Apify
print(b1) # Blog
print(c1) # Web
print(d1) # Scraping
When unpacking tuples, the number of variables on the left must match the number of values on the tuple. Otherwise, you may get errors such as "not enough values to unpack" or "too many values to unpack".
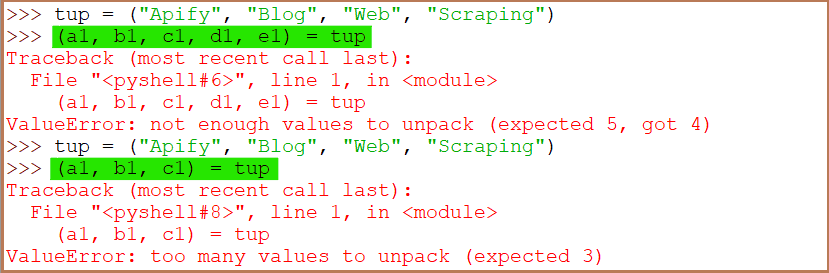
Python tuples can sometimes be created without parentheses. You can leave out the parentheses.
Named tuple
Named tuples and regular tuples consume the same amount of memory. However, named tuples increase the readability of code. With named tuples, you can access elements using their names instead of index numbers. This makes code more readable and less error-prone.
from collections import namedtuple
import sys
# named tuple
Crawl = namedtuple("Crawler", "name company stars")
crawlee = Crawl("Crawlee", "Apify", "10k")
print(crawlee)
print("Size: ", sys.getsizeof(crawlee))
# normal tuple
tup = ("Crawlee", "Apify", "10k")
print(tup)
print("Size: ", sys.getsizeof(tup))
Here’s the code output:
Crawler(name='Crawlee', company='Apify', stars='10k')
Size: 64
('Crawlee', 'Apify', '10k')
Size: 64
Do you notice the difference in the above outputs? The first output is more readable because it shows the name of the crawler, company, and stars. The second output is more concise, but it's not as easy to read. Both outputs consume the same amount of memory because named tuples are subclasses of tuples that are programmatically created to your specification, with named fields and a fixed length.
Real-world examples
You've learned a lot about tuples and lists. Now, let's explore some use cases. Let's see practically how they're utilized in real-world scenarios.
Returning values as a tuple
Let's start by looking at the real-world use case of tuple unpacking.
User-defined functions and other built-in Python functions can return values using various techniques. One common and simple way is to return values as a tuple. Then, you can unpack these values for further operations. This is a structured way to return values from a function.
def person_info():
name = "Satyam"
age = 22
city = "Delhi"
return name, age, city
# Call the function to receive multiple values in tuple form
info = person_info()
print(info)
# Unpack the returned tuple
name, age, city = person_info()
print("Name:", name)
print("Age:", age)
print("City:", city)
Here’s the code output:
('Satyam', 22, 'Delhi')
Name: Satyam
Age: 22
City: Delhi
Cool! Now let's look at another scenario.
Using tuples to store coordinates
As you know, coordinates such as longitude and latitude never change. Tuples are the best way to store these coordinates so that they cannot accidentally change.
Below, we’re storing the coordinates in tuple format. To retrieve them for further operations, simply enter the city name, and you’ll get the coordinates.
city_coordinates = {}
def add_cords(city_name, latitude, longitude):
# Storing coordinates in tuple format
city_coordinates[city_name.lower()] = (latitude, longitude)
def get_cords(city_name):
return city_coordinates.get(city_name, "City not found")
add_cords("Delhi", 40.7128, -74.0060)
add_cords("Bombay", 34.0522, -118.2437)
add_cords("Chicago", 41.8781, -87.6298)
add_cords("San Francisco", 37.7749, -122.4194)
city_name = input("City name? ")
coordinates = get_cords(city_name.lower())
print(f"Coordinates of {city_name}: {coordinates}")
Using tuples to make a contact list
Now, what if you want to make a contact list where you can store a person's information, such as name, email, or phone? You can create a list of dictionaries. This list can be updated and deleted as needed.
In the code below, we create a contact list with some information, then add some more information, and then retrieve our stored information.
contacts = [
{"name": "John Doe", "email": "john@gmail.com", "phone": "123-456-7890"},
{"name": "Jane Carle", "email": "jane@gmail.com", "phone": "987-654-3210"},
{"name": "Alice Johnson", "email": "alice@gmail.com", "phone": "555-555-5555"},
]
# Add a new contact
new_contact = {
"name": "Satyam Tripathi",
"email": "triposat@gmail.com",
"phone": "+91 852-123-456",
}
contacts.append(new_contact)
# Search for a contact
search_name = "Satyam Tripathi"
for cont in contacts:
if cont["name"] == search_name:
print("Name: ", cont["name"])
print("Email: ", cont["email"])
print("Phone: ", cont["phone"])
Using a tuple as a dictionary key
Lastly, let's look at an example of using a tuple as a dictionary key. Tuples are used because they're hashable, which allows for efficient lookups in a Python dictionary. Also, since tuples are immutable, they can be best used as keys in a Python dictionary.
In the following code, we create a tuple of customer name, purchase date, and receipt number to create a unique combination of these values. No two customers can have the same combination, so the tuple can be used as a unique identifier.
# Create a dictionary to store brand transactions
brand_transactions = {
("Satyam Tripathi", "2023-09-15", "S12U345"): 124.10,
("Bob Steel", "2023-09-16", "S12Q346"): 88.94,
("John Clark", "2023-09-15", "S12L347"): 54.45,
}
# Define customer information
customer_name = "Satyam Tripathi"
purchase_date = "2023-09-15"
receipt_number = "S12U345"
# Create a transaction key tuple
transaction_key = (customer_name, purchase_date, receipt_number)
# Check if the transaction key exists in the dictionary
if transaction_key in brand_transactions:
purchase_amount = brand_transactions[transaction_key]
print(f"{customer_name}'s purchase on {purchase_date} (Receipt {receipt_number}): ${purchase_amount:.2f}")
else:
print(f"No transaction found for {customer_name} on {purchase_date} with Receipt {receipt_number}.")
Tips and best practices
Now you know how to use tuples and lists in various real-time scenarios. Let's go through some other best practices for using lists and tuples.
If you don't want your data to be changed and prefer it to be read-only, then you should choose the tuple data type over lists.
If you know your data will grow or shrink in the future, you need to use the list data type.
When you prefer to have multiple data in a single key of a dictionary, use tuple elements as a key of a dictionary.
If you want to avoid the cost of resizing, use lists because Python doesn't resize a list every time you need to add or remove an item.
List comprehensions are a concise and powerful way to create new lists using existing lists. However, you can't do this with tuples.
When to use tuples and when to use lists
We've covered everything you need to know about Python lists and tuples. So, let's quickly sum up with when to use tuples and when to use lists:
Use a tuple (or any immutable data type) if the data you're putting into it won't be changed. Your code will be faster and more resistant to errors. Otherwise, use lists (or any other mutable data type that works for your case).