


Web scraping for AI: how to collect data for LLMs
A tutorial that shows you how to crawl, extract, and process web data to feed, fine-tune, or train large language models.


Generative AI solutions begin with web scraping
For months now, I've been bleating on about the limitations of large language models. Don't get me wrong. I think they're great for certain things. But people tend to overestimate their capabilities or misinterpret what they're supposed to be used for.
One of the limitations of LLMs, which I think is pretty well-documented now, is their inability to produce current, reliable information. Web scraping is the go-to solution for this problem.

Web scraping is not only one of the methods used to train LLMs; it's also the technique developers use to improve and customize generative AI models.
Watch Website Content Crawler in action and learn how to integrate it with LangChain in this live demo
Using web scraping tools (such as the one I'm going to use in the tutorial below) can help feed, fine-tune, or train LLMs or provide context for prompts for ChatGPT and similar language models. This can come in handy for a number of things, including:
Creating custom chatbots for customer support
Generating personalized content
Summarizing, translating, and proofreading texts at scale
Introducing Website Content Crawler for data ingestion
To feed and fine-tune LLMs, it's not enough to just scrape data. You need to process and clean it before you can use it for generative AI and machine learning. So in this tutorial, I'm going to use Website Content Crawler, which was designed specifically for this purpose. This guide will demonstrate why WCC is useful for collecting data for LLMs.
Website Content Crawler is what Apify calls an Actor (a serverless cloud program). Actors can perform anything from a simple action, such as filling out a web form or sending an email, to complex operations, such as crawling an entire website and removing duplicates from a large dataset.
Like all Apify Actors, you can run WCC via:
Web UI
Apify API
Apify CLI
If you're new to Apify, using the UI is the easiest way to test it out, so that's the method I'm going to use in this tutorial.
To use this tool and follow along with me, go to Website Content Crawler in Apify Store and click the Try for free button.
You'll need an Apify account. If you don't have one, you'll be prompted to sign up when you click that button.
Otherwise, you'll be taken straight to Apify Console (which is basically your dashboard), and you'll see the UI that I'm about to walk you through.
1. Start URLs
I'm going to use the default input and scrape the Apify docs using the following start URL: https://docs.apify.com/academy/web-scraping-for-beginners.
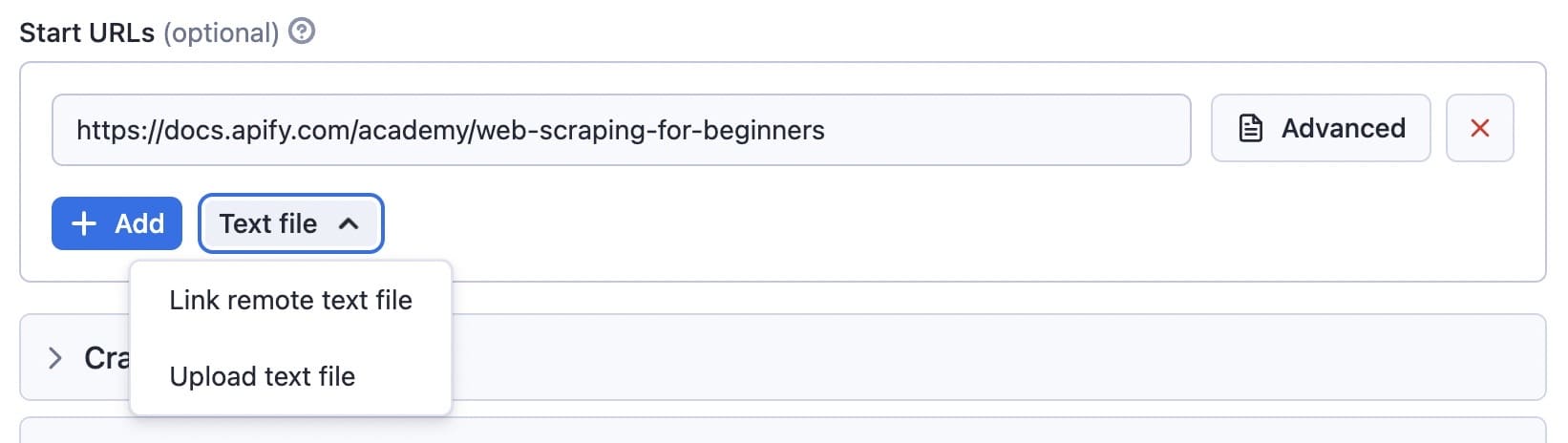
First step: Start URLs
In this case, the crawler will only crawl the links beginning with academy/.
You can add other URLs to the list, as well. These will be added to the crawler queue, and the Actor will process them one by one.
You can use the Text file option for batch processing if you have lots of URLs and want to crawl them all. You can either upload a file with a list that has each URL on a separate line, or you can provide a URL of the file.
2. Crawler settings
Crawler type
The default crawler type is Firefox. This can load most pages and is usually better for anti-bot blocking, but it’s the slowest option. Apify has set it as the default because it gets you the most consistent results. However, it requires more compute units takes longer, and therefore costs more.
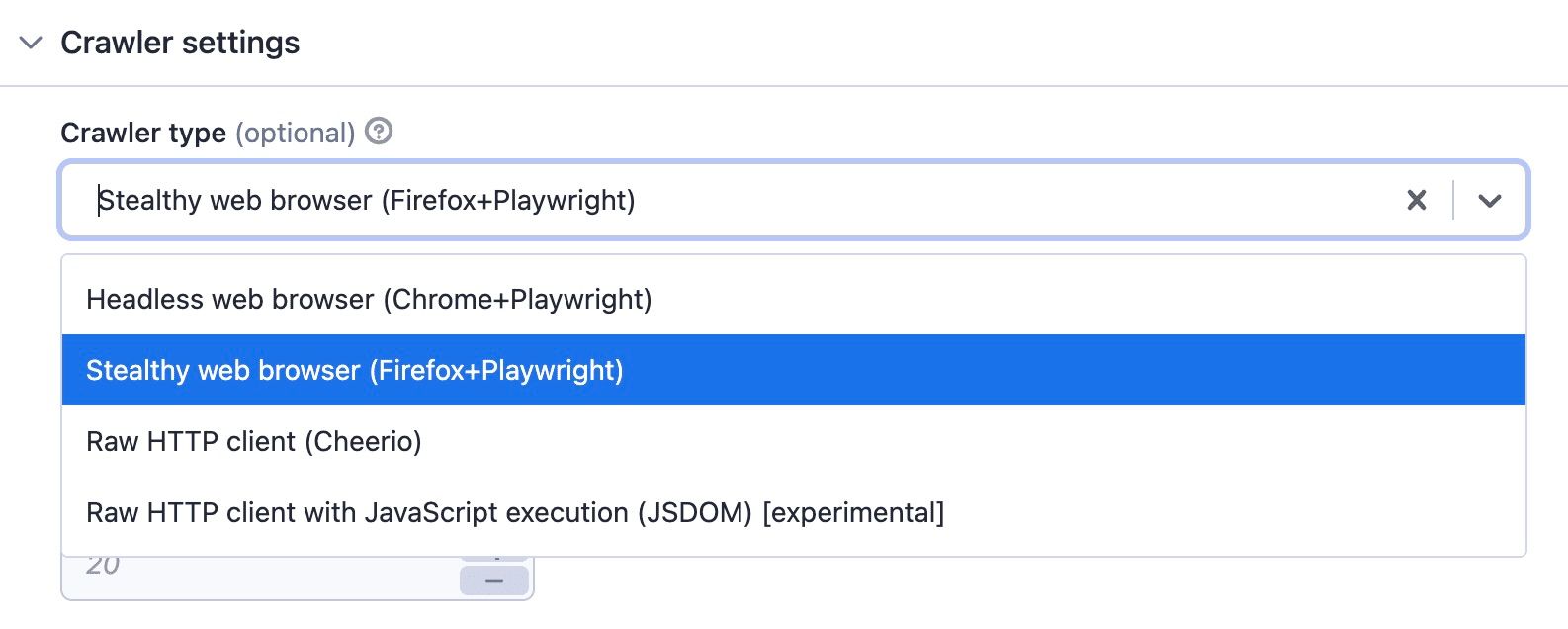
Choose crawler type
If you need a browser or wish to render client-side JavaScript, you can use the Chrome browser instead. It's faster and requires less memory, but keep in mind that it's more detectable by anti-bot protections.
Use the Raw HTTP client (Cheerio) if you don’t need JavaScript client-side rendering, as it will be 20 times faster.
If you’re feeling adventurous, you could try the experimental JSDOM option. It's much faster than browsers and provides some JS execution support. However, at this point, JSDOM’s coverage of standard web APIs is still incomplete (see this ancient issue tracking the still missing fetch implementation). So I can't wholeheartedly recommend it.
Exclude URLs (globs)
By default, the crawler will visit all the web pages in the Start URLs field (plus all the linked pages - but only if their path prefixes match). However, there might be some you don’t want to visit. If that's the case, you can use the exclude URLs (globs) option.

Fill in webpages you don't want to visit by using the exclude URLs option
You can also check if the glob matches what you want with the Test Glob button.
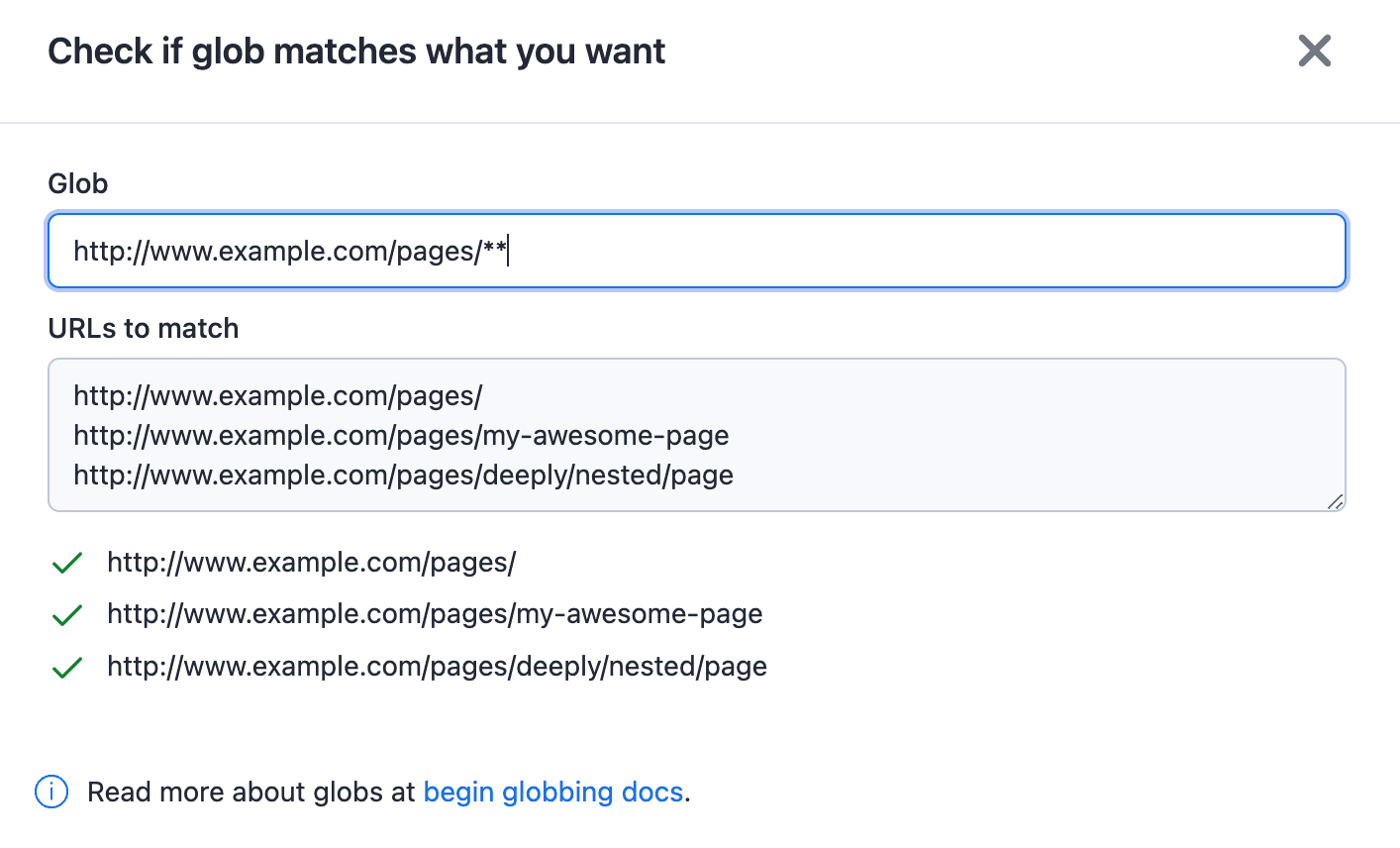
Check whether glob matches your interest with the Test Glob tool
Initial cookies
Cookies are sometimes used to identify the user with the server it’s trying to access. You can use the initial cookies option if you want to access content behind a log-in or authenticate your crawler with the website you’re scraping. Here are a couple of examples.

Use the initial cookie option to scrape the content behind a log-in
3. HTML processing
There are two steps to HTML processing: a) waiting for content to load and b) processing the HTML from the web page (data cleaning). Although the UI doesn't strictly follow this order, I've decided to break it up this way: 3. HTML processing and 4. Data cleaning.
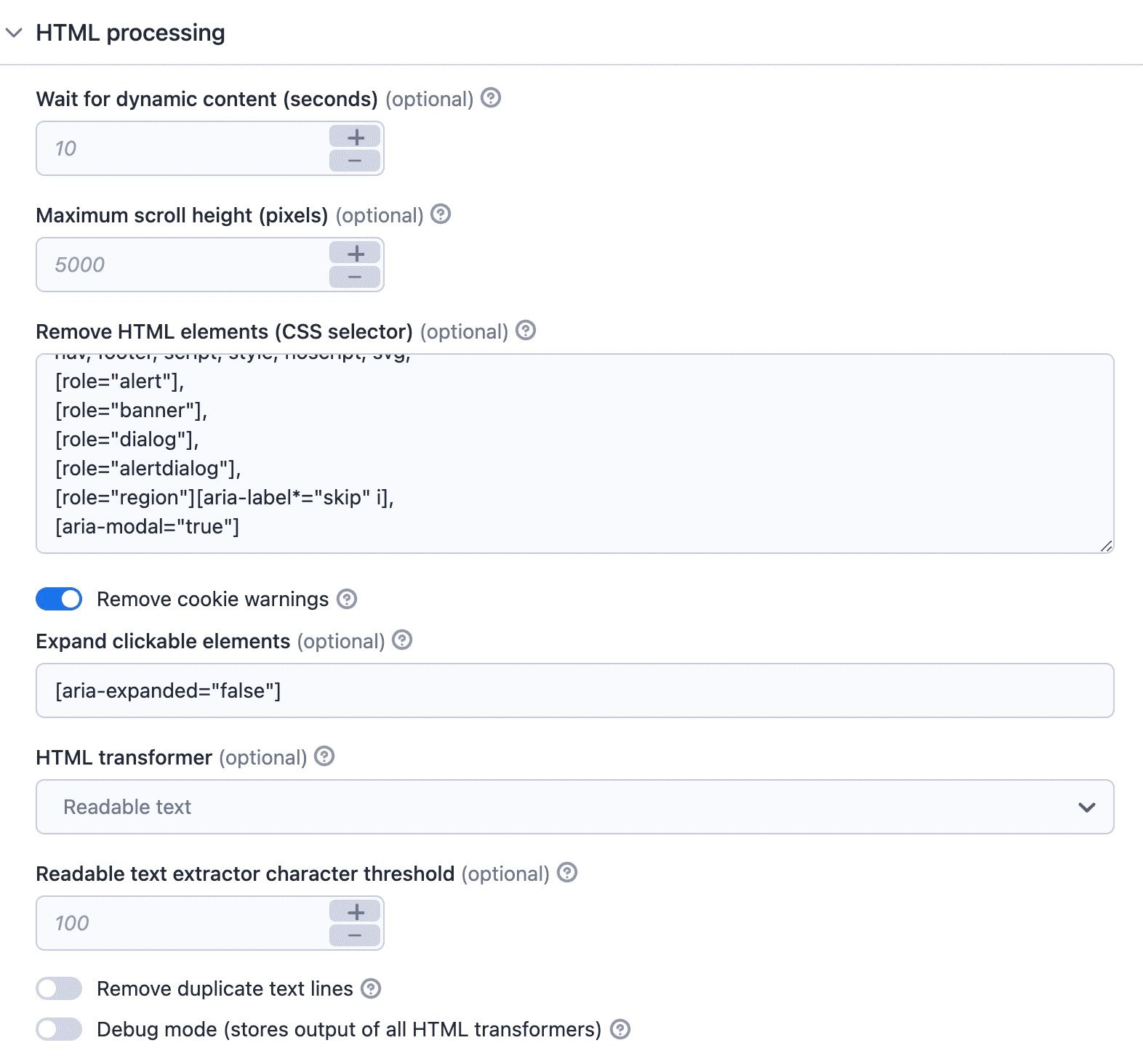
Use the HTML processing tool
Wait for dynamic content
Some web pages have lazy loading, which is when the web page loads more content as you scroll down. In such cases, you can tell the crawler to wait for dynamic content to load. The crawler will wait for up to 10 seconds as long as the web page is changing.
Maximum scroll height
The maximum scroll height is the height at which you scroll down before starting to process the page. This is there just to prevent infinite scrolling. Imagine an online store loading more and more products as you scroll, for example.
Remove cookie warnings
Once the content is loaded, the crawler may try to click on the cookie modals. With the remove cookie warnings option, it will click and hide the modals. It's enabled by default.
Expand clickable elements
The expand clickable elements option lets you add a selector of things the crawler should click on. If you don't select this, the Actor won't crawl any links in collapsed content. So use this option to scrape content from collapsed sections of the webpage.
4. Data cleaning
Remove HTML elements
You can clean the data by removing HTML elements. These are the selectors of things you don’t want to include in your results (banners, ads, menus, alerts, and so on). The default setting covers most things, but you can add more to the list if you need to. This way, you'll have only the content you need to feed your language model.
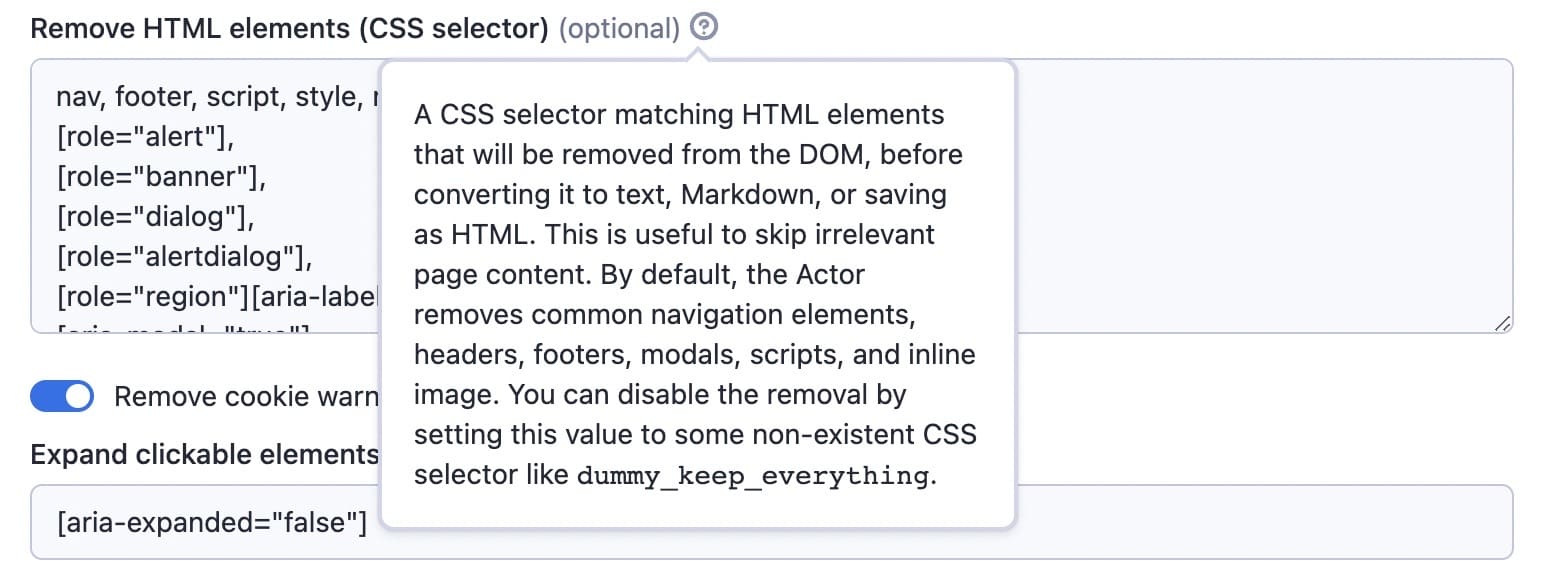
Remove banners, ads, menus, and other HTML elements
HTML transformer
With this option, you can try to remove more elements, but it may strip useful parts of the content you want to extract. So, if you discover that this is the case after running the Actor, you can choose None.
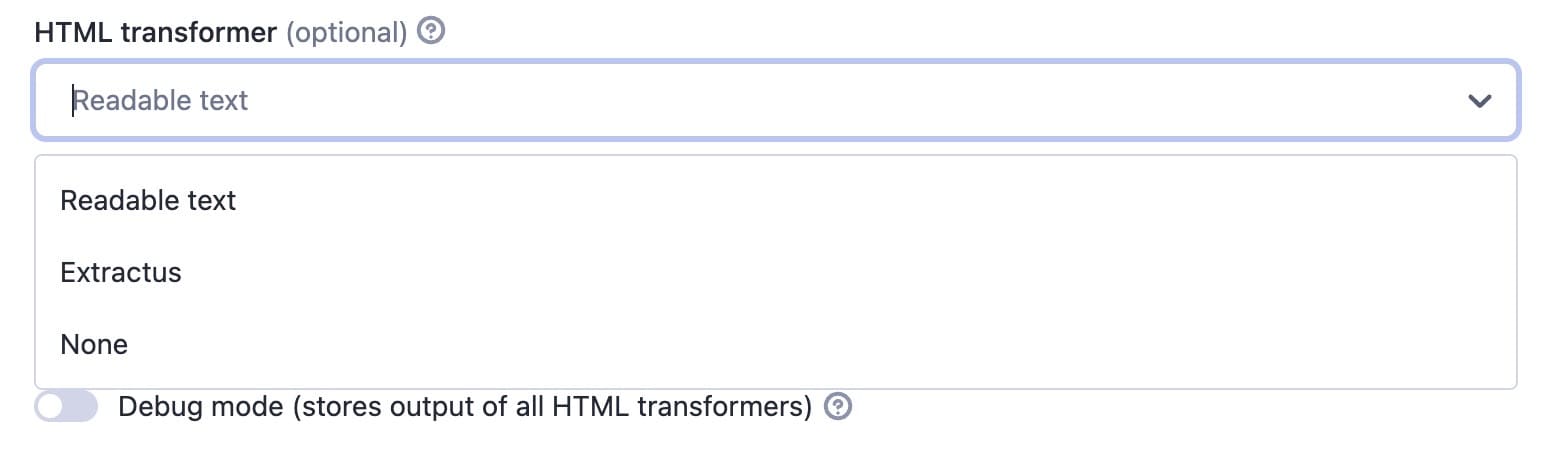
Pay attention to HTML transformer options
Remove duplicate text lines
You can remove duplicate text lines if the crawler keeps seeing the same line again and again. You can enable this in case you keep seeing some parts of footers or menus in your output but you don’t want to look for the correct CSS selectors. The Actor strips the repeated content after 4 or 5 occurrences. This will prevent saving the same information repeatedly and so keep the data clean.
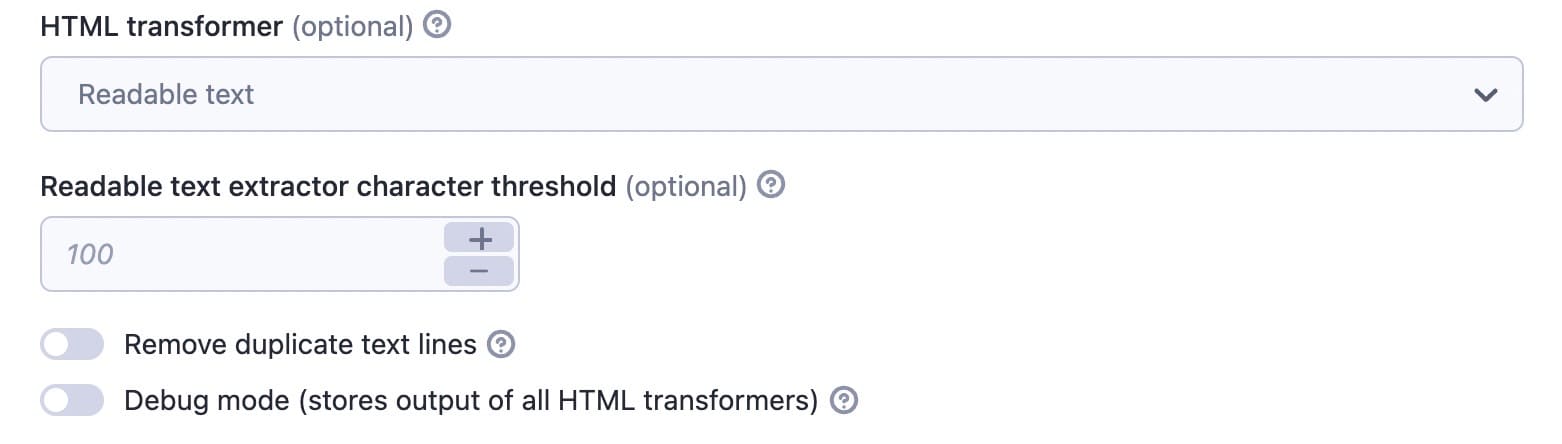
Use HTML transformer to remove duplicate text lines
5. Output settings
You can save the data as HTML or Markdown or save screenshots if you're using a headless browser. The Save files option deserves some special attention, though.
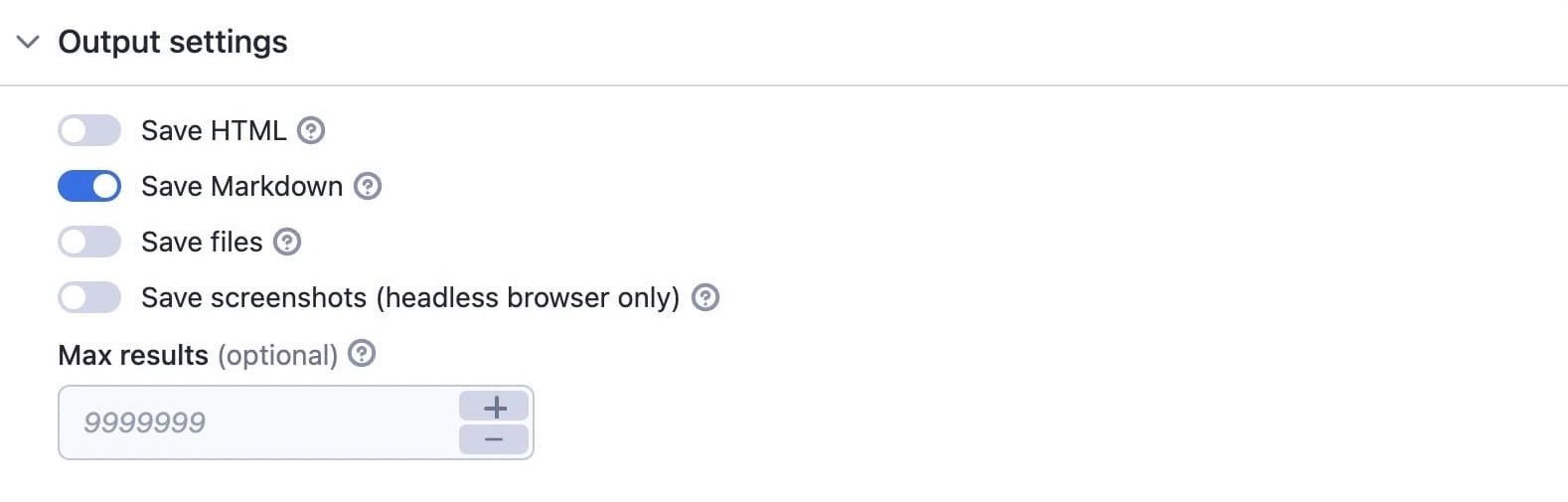
Choose the output setting that fits your needs
If you choose Save files, the crawler inspects the web page, and whenever it sees a link that goes to, say a PDF, Word doc, or Excel sheet, it will download it to the Apify key-value store.
6. Running the Actor
With the UI, you can execute code with the click of a button (the Start button at the bottom of the screen).
While running, you'll see what the crawler is up to in the log and can check if it's experiencing any issues. You can abort the run at any point.
When the crawler has completed a successful run, you can retrieve the data from the output tab.
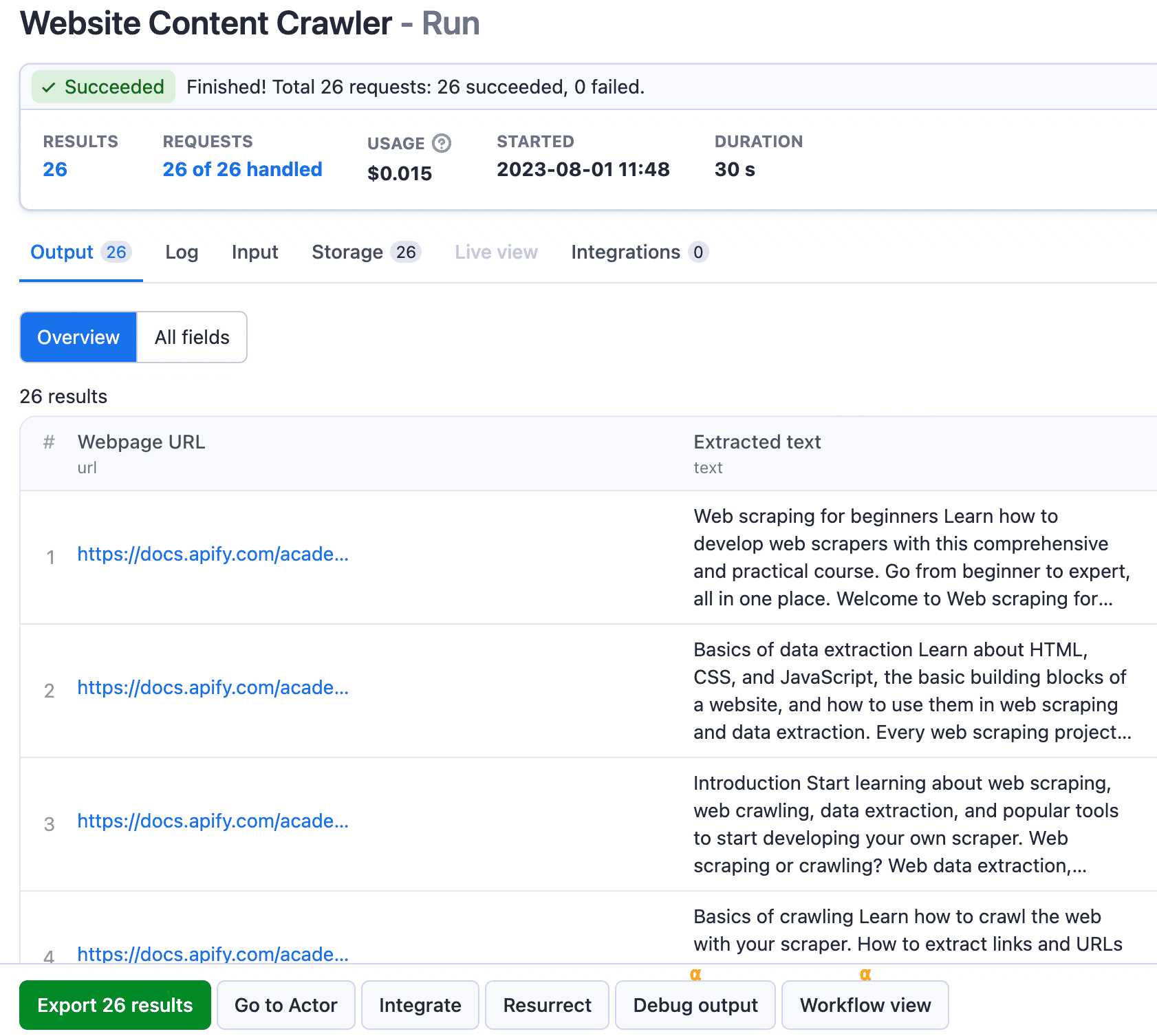
Run the Website Content Crawler
7. Storing the data
The results of the Actor are stored in the default Dataset associated with the Actor run, from where you can access it via API and export it to formats like JSON, XML, or CSV.
With the UI, you need only click the Export results button to view or download the data in your preferred format.
By way of example, here's the data in JSON from the first of the 26 results I got from this demo run using the UI's default settings.
{
"url": "https://docs.apify.com/academy/web-scraping-for-beginners",
"crawl": {
"loadedUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"loadedTime": "2023-08-01T09:48:51.180Z",
"referrerUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"depth": 0,
"httpStatusCode": 200
},
"metadata": {
"canonicalUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"title": "Web scraping for beginners | Academy | Apify Documentation",
"description": "Learn how to develop web scrapers with this comprehensive and practical course. Go from beginner to expert, all in one place.",
"author": null,
"keywords": null,
"languageCode": "en"
},
"screenshotUrl": null,
"text": "Web scraping for beginners\nLearn how to develop web scrapers with this comprehensive and practical course. Go from beginner to expert, all in one place.\nWelcome to Web scraping for beginners, a comprehensive, practical and long form web scraping course that will take you from an absolute beginner to a successful web scraper developer. If you're looking for a quick start, we recommend trying this tutorial instead.\nThis course is made by Apify, the web scraping and automation platform, but we will use only open-source technologies throughout all academy lessons. This means that the skills you learn will be applicable to any scraping project, and you'll be able to run your scrapers on any computer. No Apify account needed.\nIf you would like to learn about the Apify platform and how it can help you build, run and scale your web scraping and automation projects, see the Apify platform course, where we'll teach you all about Apify serverless infrastructure, proxies, API, scheduling, webhooks and much more.\nWhy learn scraper development?\nWith so many point-and-click tools and no-code software that can help you extract data from websites, what is the point of learning web scraper development? Contrary to what their marketing departments say, a point-and-click or no-code tool will never be as flexible, as powerful, or as optimized as a custom-built scraper.\nAny software can do only what it was programmed to do. If you build your own scraper, it can do anything you want. And you can always quickly change it to do more, less, or the same, but faster or cheaper. The possibilities are endless once you know how scraping really works.\nScraper development is a fun and challenging way to learn web development, web technologies, and understand the internet. You will reverse-engineer websites and understand how they work internally, what technologies they use and how they communicate with their servers. You will also master your chosen programming language and core programming concepts. When you truly understand web scraping, learning other technology like React or Next.js will be a piece of cake.\nCourse Summary\nWhen we set out to create the Academy, we wanted to build a complete guide to modern web scraping - a course that a beginner could use to create their first scraper, as well as a resource that professionals will continuously use to learn about advanced and niche web scraping techniques and technologies. All lessons include code examples and code-along exercises that you can use to immediately put your scraping skills into action.\nThis is what you'll learn in the Web scraping for beginners course:\nWeb scraping for beginners\nBasics of data extraction\nBasics of crawling\nBest practices\nRequirements\nYou don't need to be a developer or a software engineer to complete this course, but basic programming knowledge is recommended. Don't be afraid, though. We explain everything in great detail in the course and provide external references that can help you level up your web scraping and web development skills. If you're new to programming, pay very close attention to the instructions and examples. A seemingly insignificant thing like using [] instead of () can make a lot of difference.\nIf you don't already have basic programming knowledge and would like to be well-prepared for this course, we recommend taking a JavaScript course and learning about CSS Selectors.\nAs you progress to the more advanced courses, the coding will get more challenging, but will still be manageable to a person with an intermediate level of programming skills.\nIdeally, you should have at least a moderate understanding of the following concepts:\nJavaScript + Node.js\nIt is recommended to understand at least the fundamentals of JavaScript and be proficient with Node.js prior to starting this course. If you are not yet comfortable with asynchronous programming (with promises and async...await), loops (and the different types of loops in JavaScript), modularity, or working with external packages, we would recommend studying the following resources before coming back and continuing this section:\nasync...await (YouTube)\nJavaScript loops (MDN)\nModularity in Node.js\nGeneral web development\nThroughout the next lessons, we will sometimes use certain technologies and terms related to the web without explaining them. This is because the knowledge of them will be assumed (unless we're showing something out of the ordinary).\nHTML\nHTTP protocol\nDevTools\njQuery or Cheerio\nWe'll be using the Cheerio package a lot to parse data from HTML. This package provides a simple API using jQuery syntax to help traverse downloaded HTML within Node.js.\nNext up\nThe course begins with a small bit of theory and moves into some realistic and practical examples of extracting data from the most popular websites on the internet using your browser console. So let's get to it!\nIf you already have experience with HTML, CSS, and browser DevTools, feel free to skip to the Basics of crawling section.",
"markdown": "## Web scraping for beginners\n\n**Learn how to develop web scrapers with this comprehensive and practical course. Go from beginner to expert, all in one place.**\n\n* * *\n\nWelcome to **Web scraping for beginners**, a comprehensive, practical and long form web scraping course that will take you from an absolute beginner to a successful web scraper developer. If you're looking for a quick start, we recommend trying [this tutorial](https://blog.apify.com/web-scraping-javascript-nodejs/) instead.\n\nThis course is made by [Apify](https://apify.com/), the web scraping and automation platform, but we will use only open-source technologies throughout all academy lessons. This means that the skills you learn will be applicable to any scraping project, and you'll be able to run your scrapers on any computer. No Apify account needed.\n\nIf you would like to learn about the Apify platform and how it can help you build, run and scale your web scraping and automation projects, see the [Apify platform course](https://docs.apify.com/academy/apify-platform), where we'll teach you all about Apify serverless infrastructure, proxies, API, scheduling, webhooks and much more.\n\n## Why learn scraper development?[](#why-learn \"Direct link to Why learn scraper development?\")\n\nWith so many point-and-click tools and no-code software that can help you extract data from websites, what is the point of learning web scraper development? Contrary to what their marketing departments say, a point-and-click or no-code tool will never be as flexible, as powerful, or as optimized as a custom-built scraper.\n\nAny software can do only what it was programmed to do. If you build your own scraper, it can do anything you want. And you can always quickly change it to do more, less, or the same, but faster or cheaper. The possibilities are endless once you know how scraping really works.\n\nScraper development is a fun and challenging way to learn web development, web technologies, and understand the internet. You will reverse-engineer websites and understand how they work internally, what technologies they use and how they communicate with their servers. You will also master your chosen programming language and core programming concepts. When you truly understand web scraping, learning other technology like React or Next.js will be a piece of cake.\n\n## Course Summary[](#summary \"Direct link to Course Summary\")\n\nWhen we set out to create the Academy, we wanted to build a complete guide to modern web scraping - a course that a beginner could use to create their first scraper, as well as a resource that professionals will continuously use to learn about advanced and niche web scraping techniques and technologies. All lessons include code examples and code-along exercises that you can use to immediately put your scraping skills into action.\n\nThis is what you'll learn in the **Web scraping for beginners** course:\n\n* [Web scraping for beginners](https://docs.apify.com/academy/web-scraping-for-beginners)\n * [Basics of data extraction](https://docs.apify.com/academy/web-scraping-for-beginners/data-extraction)\n * [Basics of crawling](https://docs.apify.com/academy/web-scraping-for-beginners/crawling)\n * [Best practices](https://docs.apify.com/academy/web-scraping-for-beginners/best-practices)\n\n## Requirements[](#requirements \"Direct link to Requirements\")\n\nYou don't need to be a developer or a software engineer to complete this course, but basic programming knowledge is recommended. Don't be afraid, though. We explain everything in great detail in the course and provide external references that can help you level up your web scraping and web development skills. If you're new to programming, pay very close attention to the instructions and examples. A seemingly insignificant thing like using `[]` instead of `()` can make a lot of difference.\n\n> If you don't already have basic programming knowledge and would like to be well-prepared for this course, we recommend taking a [JavaScript course](https://www.codecademy.com/learn/introduction-to-javascript) and learning about [CSS Selectors](https://www.w3schools.com/css/css_selectors.asp).\n\nAs you progress to the more advanced courses, the coding will get more challenging, but will still be manageable to a person with an intermediate level of programming skills.\n\nIdeally, you should have at least a moderate understanding of the following concepts:\n\n### JavaScript + Node.js[](#javascript-and-node \"Direct link to JavaScript + Node.js\")\n\nIt is recommended to understand at least the fundamentals of JavaScript and be proficient with Node.js prior to starting this course. If you are not yet comfortable with asynchronous programming (with promises and `async...await`), loops (and the different types of loops in JavaScript), modularity, or working with external packages, we would recommend studying the following resources before coming back and continuing this section:\n\n* [`async...await` (YouTube)](https://www.youtube.com/watch?v=vn3tm0quoqE&ab_channel=Fireship)\n* [JavaScript loops (MDN)](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Loops_and_iteration)\n* [Modularity in Node.js](https://www.section.io/engineering-education/how-to-use-modular-patterns-in-nodejs/)\n\n### General web development[](#general-web-development \"Direct link to General web development\")\n\nThroughout the next lessons, we will sometimes use certain technologies and terms related to the web without explaining them. This is because the knowledge of them will be **assumed** (unless we're showing something out of the ordinary).\n\n* [HTML](https://developer.mozilla.org/en-US/docs/Web/HTML)\n* [HTTP protocol](https://developer.mozilla.org/en-US/docs/Web/HTTP)\n* [DevTools](https://docs.apify.com/academy/web-scraping-for-beginners/data-extraction/browser-devtools)\n\n### jQuery or Cheerio[](#jquery-or-cheerio \"Direct link to jQuery or Cheerio\")\n\nWe'll be using the [**Cheerio**](https://www.npmjs.com/package/cheerio) package a lot to parse data from HTML. This package provides a simple API using jQuery syntax to help traverse downloaded HTML within Node.js.\n\n## Next up[](#next \"Direct link to Next up\")\n\nThe course begins with a small bit of theory and moves into some realistic and practical examples of extracting data from the most popular websites on the internet using your browser console. So [let's get to it!](https://docs.apify.com/academy/web-scraping-for-beginners/introduction)\n\n> If you already have experience with HTML, CSS, and browser DevTools, feel free to skip to the [Basics of crawling](https://docs.apify.com/academy/web-scraping-for-beginners/crawling) section."
Integrating your data with LangChain, Pinecone, and other tools
You can now use the data you've collected to feed and fine-tune LLMs by integrating your data with LangChain or with a vector database such as Pinecone or any Pinecone alternatives.
For a detailed example, check out this tutorial on how to use LangChain and Pinecone with Apify.