

Web scraping: how to crawl without getting blocked
Your go-to guide on how to choose proxies wisely, fight Cloudflare, solve CAPTCHAs, and avoid honeytraps.


So you thought data extraction was difficult? Well, try getting through the website’s anti-scraping protections first. Any weathered web automation developer will confirm that extracting data is the last and easiest step of web scraping. It only comes after dodging IP-rate limiting, switching user agents, trial and error with Cloudflare, and lots of other possible roadblocks on the way to consistent and reliable web scraping. (Un)fortunately, these issues are quite common, so there are always solutions at hand – some elegant, some clunky, but never one-size-fits-all.
It is probably no secret to you that the key to winning this obstacle race is to make your scraping activities appear as human-like (digitally speaking) as possible. Let’s run through some of the most common issues and the tried-and-tested countermeasures to avoid getting blocked while scraping.
Common mistakes when web scraping that lead to blocking
You might not face any issues when crawling smaller or less established websites. But when you try web scraping on websites with greater traffic, dynamically loading pages, or even Google you might find your requests ignored, receive authorization errors such as 403, or get your IP blocked.
Most of the time, you will have to fit your weapon to the one your adversary uses. So if the website is introducing IP rate limits, your best bet is to use proxies. If it throws you a Captcha, then it’s time to find an AntiCaptcha. And so on. Now let’s go into detail about each anti-scraping method and its mitigation.
#1 🛡️ Choose proxies and rotate IP sessions to avoid IP rate limiting
Very often, websites will limit the number of requests from a specific IP address after a certain number of visits within a short period of time. The rule here is simple: your scraper exceeds the IP rate limit -> your requests may be blocked or slowed down until the rate limit resets. In this scenario, you may also be presented with an opportunity to prove yourself as a regular user and solve a CAPTCHA. This IP-rate limiting measure is typically used for preventing DDOS attacks but also doubles as anti-scraping protection.
Sometimes websites will block the IP address even before you start scraping. This is often used to prevent excessive requests from a range of IP addresses that have already displayed signs of unwelcome behavior in the past, in our case – acting like a bot.
To avoid both of these IP-blocking scenarios, you’ll need your cloud-based web scraper to send every scraping request with a different IP. And unless you have and are willing to switch between a bunch of different devices with different internet providers, you’ll inevitably have to add some proxy service to your scraping formula.
How to choose a proxy?
The choice of proxy provider and even proxy type for web scraping can be dictated by many factors. Those include how sophisticated the anti-scraping methods are, how many web pages you want to scrape, and your budget, of course. Proxy services such as BrightData, Oxylabs or Apify will provide you with a pool of IP addresses to use for each scraping request. Just be careful not to “burn” them too fast.
🛡 Learn how to keep your proxies healthy and reduce proxy costs
The type of proxies most prone to getting burned (read: blocked) are datacenter proxies. They are easier to get blacklisted, but easier and cheaper to start with. For websites that have advanced bot detection mechanisms, you’ll have to use either mobile or residential proxies. We cover both types in a different article:
In any case, it's important to rotate your proxies efficiently. Web scrapers with proxy rotation enabled switch the IP addresses they use to access websites. This makes each request seem like it's coming from a different user. Using proxy rotation reduces the chance of blocking by making the scraper look more human-like. Instead of looking like one user accessing a thousand pages, it looks like a hundred users accessing 10 pages.
Let’s see an example of adding an authenticated proxy to the popular JavaScript HTTP client with over 20 million weekly downloads, Got:
import got from 'got';
import { HttpProxyAgent } from 'hpagent';
const response = await got('https://example.com', {
agent: {
http: new HttpProxyAgent({
proxy: `http://country-US,groups-RESIDENTIAL:p455w0rd@proxy.apify.com:8000`
})
},
});
Originally we wanted to use Axios, but it is quite complicated for a simple example to add a proxy to Axios.
Notice the country-US, groups-RESIDENTIAL username in the example proxy URL. Most modern proxy services allow configuration of the proxy through the username. In this case, country-US means that only proxies from the United States will be chosen and groups-RESIDENTIAL limits the selection to residential proxies.
The example is based on Apify Proxy, but other providers' configurations are extremely similar. Using a configurable proxy like this (a so-called super-proxy) is much more convenient than the good old IP lists we're all used to.
⬆️ What are the best proxy providers for web scraping in 2023?
Things to keep in mind when using proxy rotation
When using free proxies automate your proxy rotation to prevent disruptions to your scraping. Free proxies are often used by too many users, which makes them unreliable and quickly blacklisted by anti-scraping measures. At some point, you should consider using paid proxies.
It's also worth considering matching the location of the proxy IP address with the website you're trying to scrape. For example, if the website is based in the US, you may need to use a US-based proxy.
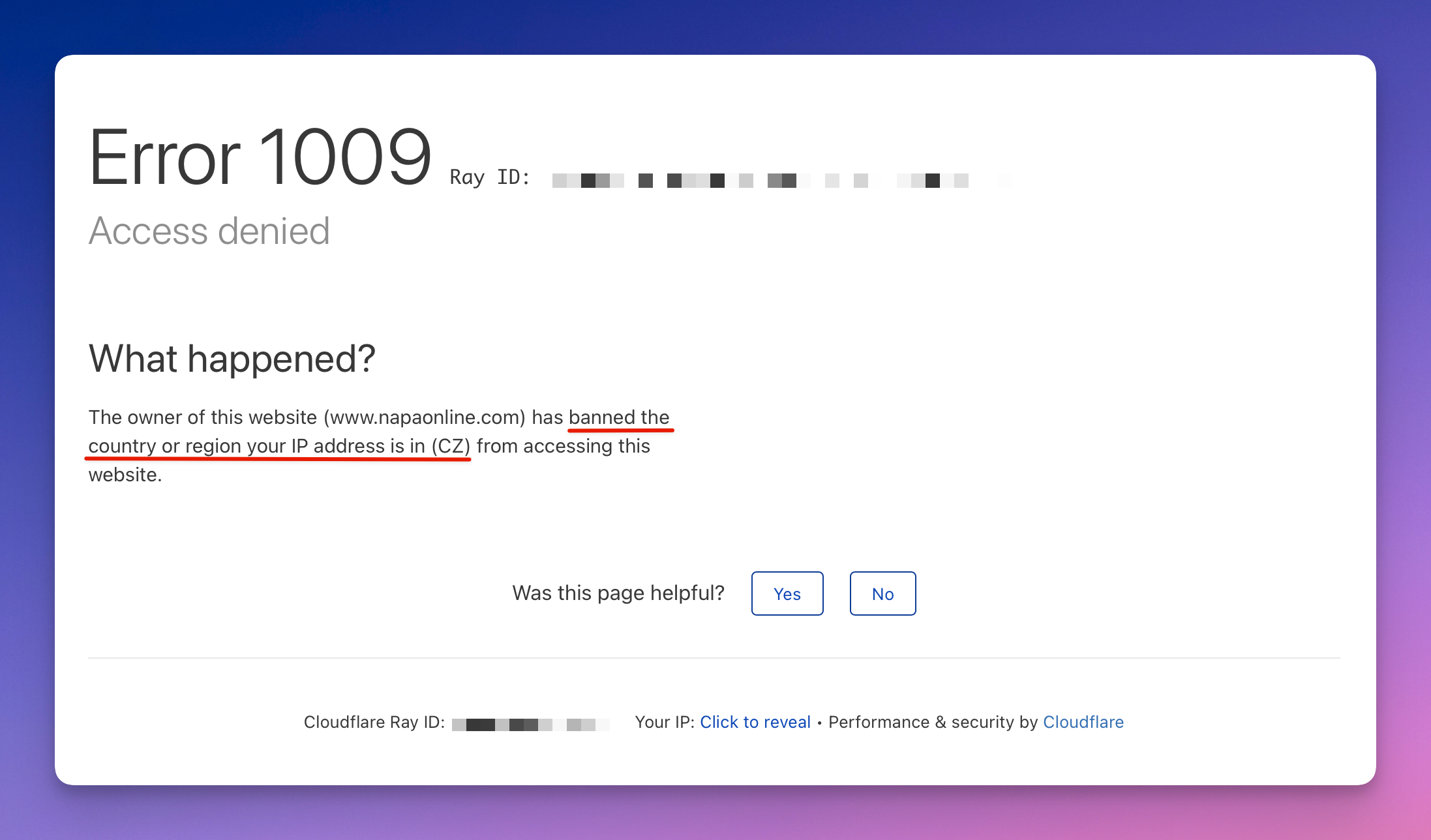
Error 1009: getting banned because of proxy location choice
- Finally, avoid using IP addresses that are in a sequence or range, as this can be easily detected by anti-scraping tools.
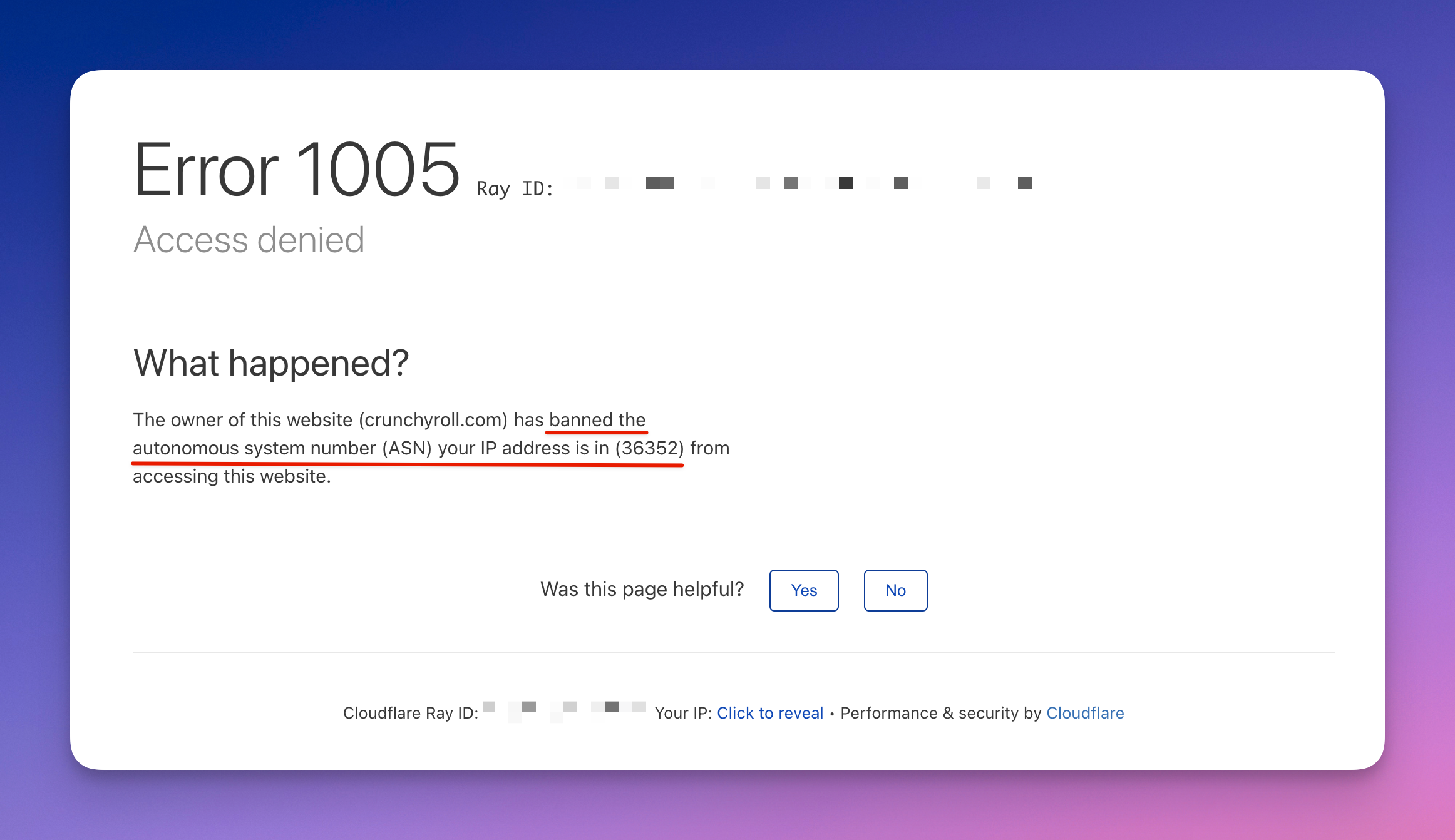
Error 1005: getting banned because of using an IP address in a sequence or range
Level up with IP sessions
Rotating residential proxies will enable you to easily change locations. But with all the freedom that proxies give, they will not make your scraping request seem human-like. The IP sessions might, though. Let's look at why.
You can use rotating proxies to change your location to thousands of different places within an hour. Simple websites won't block you for this, but if the website’s anti-scraping techniques are evolved enough to identify that this behavior is coming from the same user (usually by fingerprints), you will need a smarter way to switch your proxies, because real humans don't teleport around the world at lightspeed. You need to reuse the same IP address - but just enough times before switching to a new one. Meaning you need an IP session.
What is an IP session?
When web scraping, it's possible to reuse the same IP address by creating an IP session. This is a configuration option that all the major proxy providers have, and it's available for both datacenter and residential proxies. When you're using a list of IPs, a session is a single IP from this list.
You could program your proxies to change every five requests, but what if the IP gets blocked on the first request? Your system would keep using it, further damaging its reputation. Good session rotation should solve those use cases:
precisely control IP rotation; you should spread the load evenly over the IPs
remove IPs that hit a rate limit from rotation, letting them cool down
stop using IPs that were accidentally blacklisted (403 errors, 500 errors, network errors) to prevent damaging their reputation further
combine IPs, headers and cookies into human-like sessions that are much less likely to get blocked
This is not very convenient to do yourself, so you can use open-source libraries like Crawlee or Got-Scraping to do it for you. Got-Scraping is a scraping extension of the popular HTTP client Got we mentioned earlier.
We cover proxy rotation and sessions in depth in our guide on keeping your proxies healthy.
Now that we’ve dealt with sessions, let’s try to make our scraping requests even more human. Welcome to browser header rotation.
#2 📇 Make sure you use correct browser headers and user agents
Every time you go on a website through a browser, the browser sends a set of HTTP headers. Every browser has this set quite differently, and the website uses them to identify you as a separate user and serve you the best user experience in terms of screen size, language, type of content your browser can display, etc. However, since using a browser is also the ultimate non-bot way of visiting a website, websites use the HTTP headers and other data as proof that the visitor is human. And weaponize it against web scrapers.
Here’s an example of browser headers for Mozilla Firefox on a MacBook:
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/109.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,\*/\*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
TE: trailers
Depending on the case, the website may require some additional headers, or vice versa, omit some of them. Headers vary a lot based on the browser version and its settings, and device. Chrome on a Mac will be slightly different from the Firefox headers above.
Why are we talking about them? Because imitating headers is key to avoiding blocking. Of course, you can make a web scraper that sends requests without accompanying headers, but how long will it hold up?
A naive solution to making your scraper more human-like is simply copying and pasting these headers into the header object in your code. Paired with IP rotation, it will make your scraper more resilient, allowing you to scrape websites.
For a production solution, you have to know the right way to construct a header though. And you need to be able to construct them automatically for thousands or millions of requests.
Tips on using HTTP headers in web scraping
- Keep them consistent with the user-agent
HTTP header sets vary depending on browser, device and version of the HTTP protocol. Which is why they have to be consistent with the said parameters. User agent is one of the most common browser headers, and it’s often talked about separately from the others. It sets the tone for other headers as it identifies the type of browser, device and operating system of the user. The other headers must follow through. So when scraping a website, it's important to match the user-agent with the rest of the headers in the request. If the headers do not match the expected format, the website may detect the request as coming from a scraper and blacklist it.
For example, if the website sees a request from a Mac user using Mozilla, it will expect to see a certain set of headers along with that user-agent, let’s say 7 of them. If those headers don't show up or don’t match, the website might suspect something's fishy and block your requests. It’s like a strict dress code.
For instance, the browser compatibility table of MDN shows that Safari does not send the Sec-Fetch-Site header, but all the other browsers do. Including this header with a Safari user-agent header might flag you as a fake user since Safari doesn't use this header. At the same time, not including it when using Chrome or Firefox can get you blocked as well.
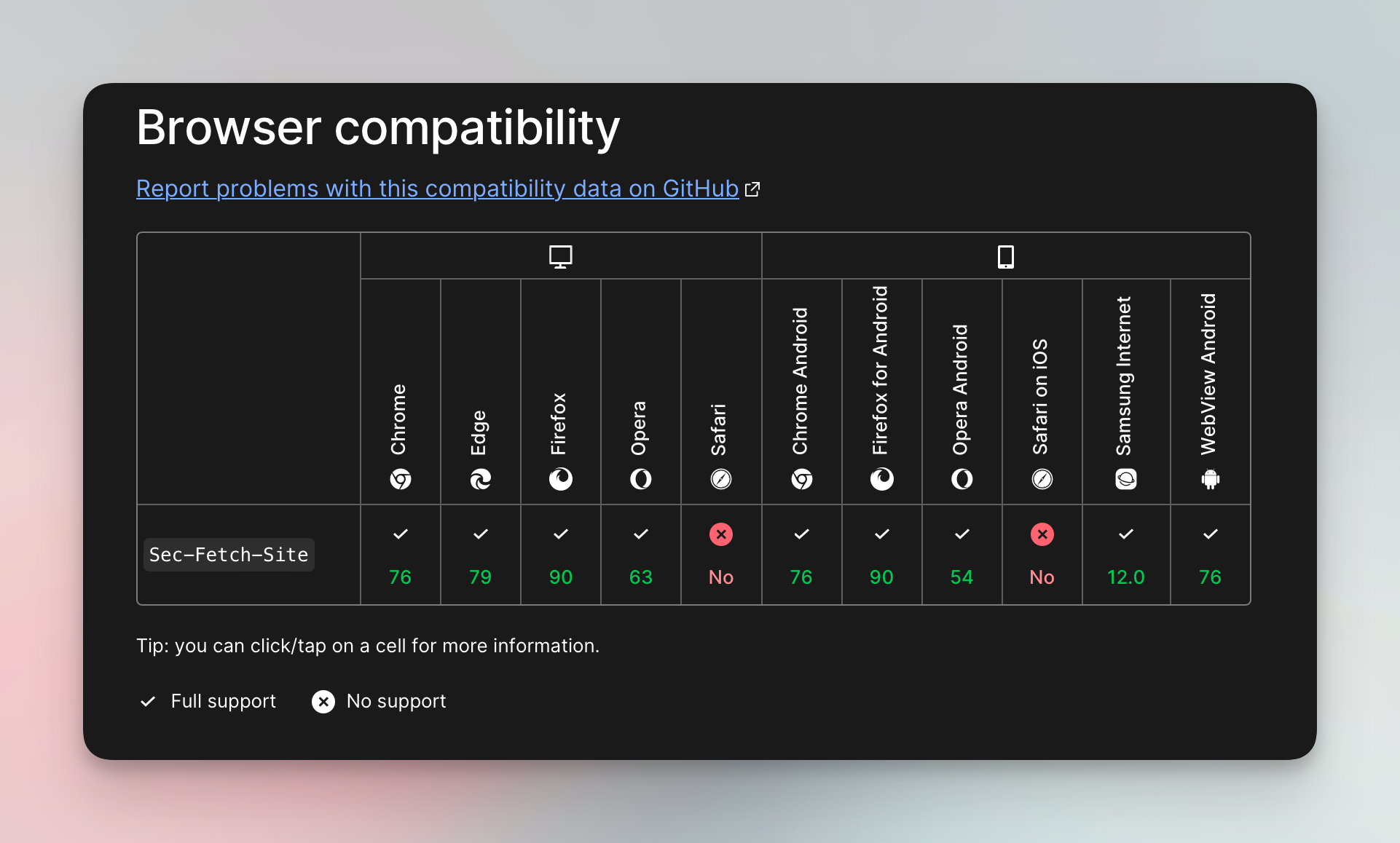
Browser compatibility example for Sec-Fetch-Site header
In general, the more detailed and accurate your header sets are, the more likely it is that your scraper’s requests will blend in.
- Don’t forget about the Referer
This one is easier. The “Referer” (yes, with one R, it’s an ages old bug) is an HTTP request header that indicates the URL of the website that brought you to the current page. A good example would be google.com. See all the headers that Chrome sends to amazon.com when you click a link on google.com:
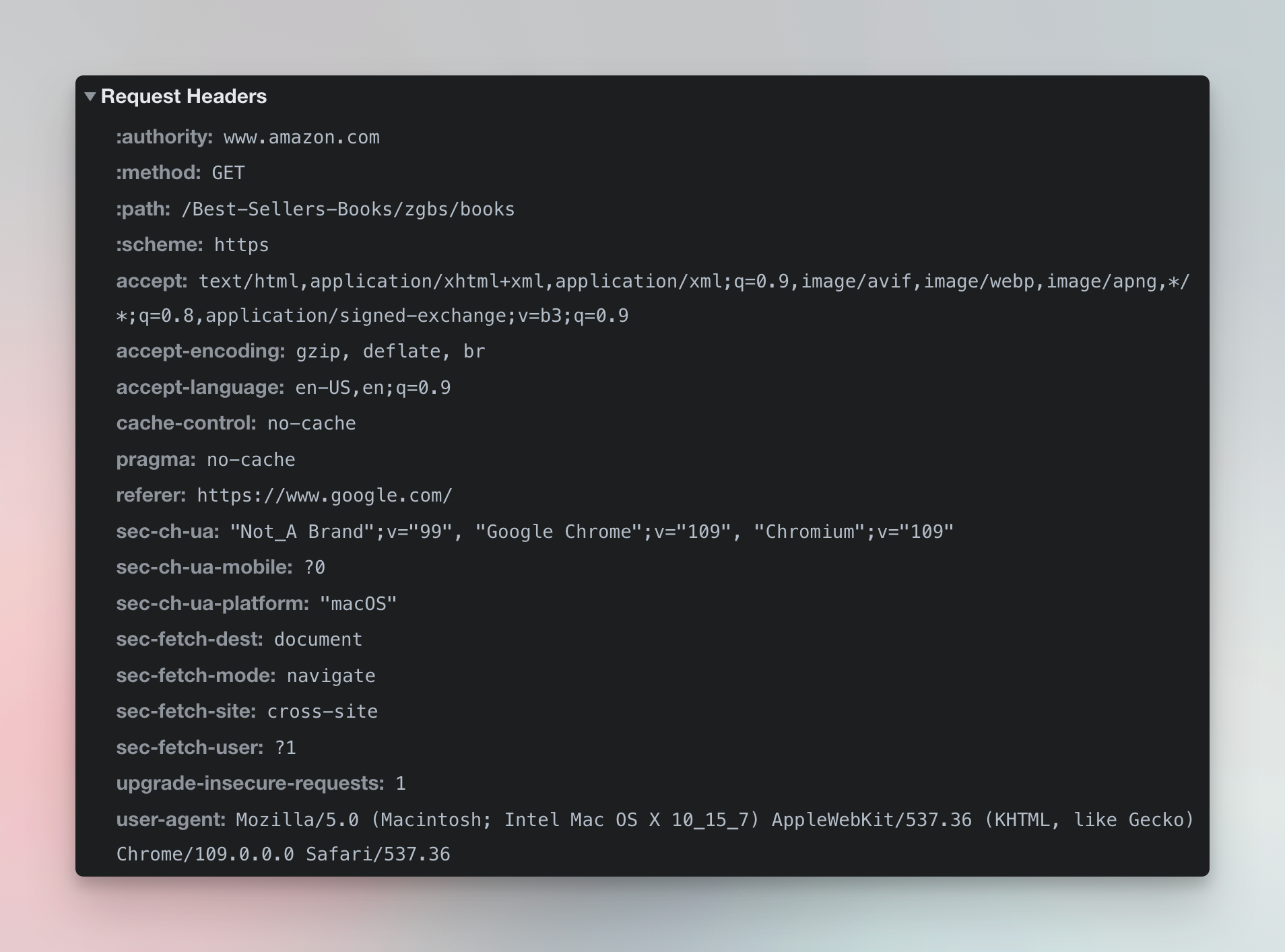
Headers that Chrome sends to amazon.com when clicking on a link on google.com
It’s also advisable to match the Google top level domain (TLD) with the country of the scraped website. If you’re scraping amazon.de, having google.de in the referer is a sign of an organic visit. If you also match the whole thing with a German proxy, you’re on the right track to avoid getting blocked. If you don’t feel like playing with TLDs then feel free to find other common referers among social media, like Facebook or Twitter.
- Consider automating it
Of course, you can write this down manually every time and create your own pool of matching headers, but if you're a JavaScript developer, we recommend using Got-Scraping, which generates all the matching headers for you and even correctly resolves HTTP vs. HTTP2. A simple example looks like this:
import { gotScraping } from 'got-scraping';
const response = await gotScraping({
url: 'https://example.com',
headerGeneratorOptions:{
devices: ['desktop'],
locales: ['en-US'],
operatingSystems: ['windows'],
},
proxyUrl: `http://session-bFlMpSvZ:p455w0rd@proxy.apify.com:8000`,
});
🖖 Generate browser fingerprints
Aside from requesting HTTP headers info, sophisticated anti-blocking systems can take it a step further and check your in-browser JavaScript environment. Parameters in that environment (Web APIs) can be even more detailed than the headers, check out the list yourself. That being said, if your headers are presenting the scraper as a vertical Android phone, and your Web APIs indicate towards a bigger horizontal screen with no touchscreen points - you’re in trouble.
See the sheer amount of data available about your browser using the navigator property, user-agent included. And this is only one of the many web APIs.
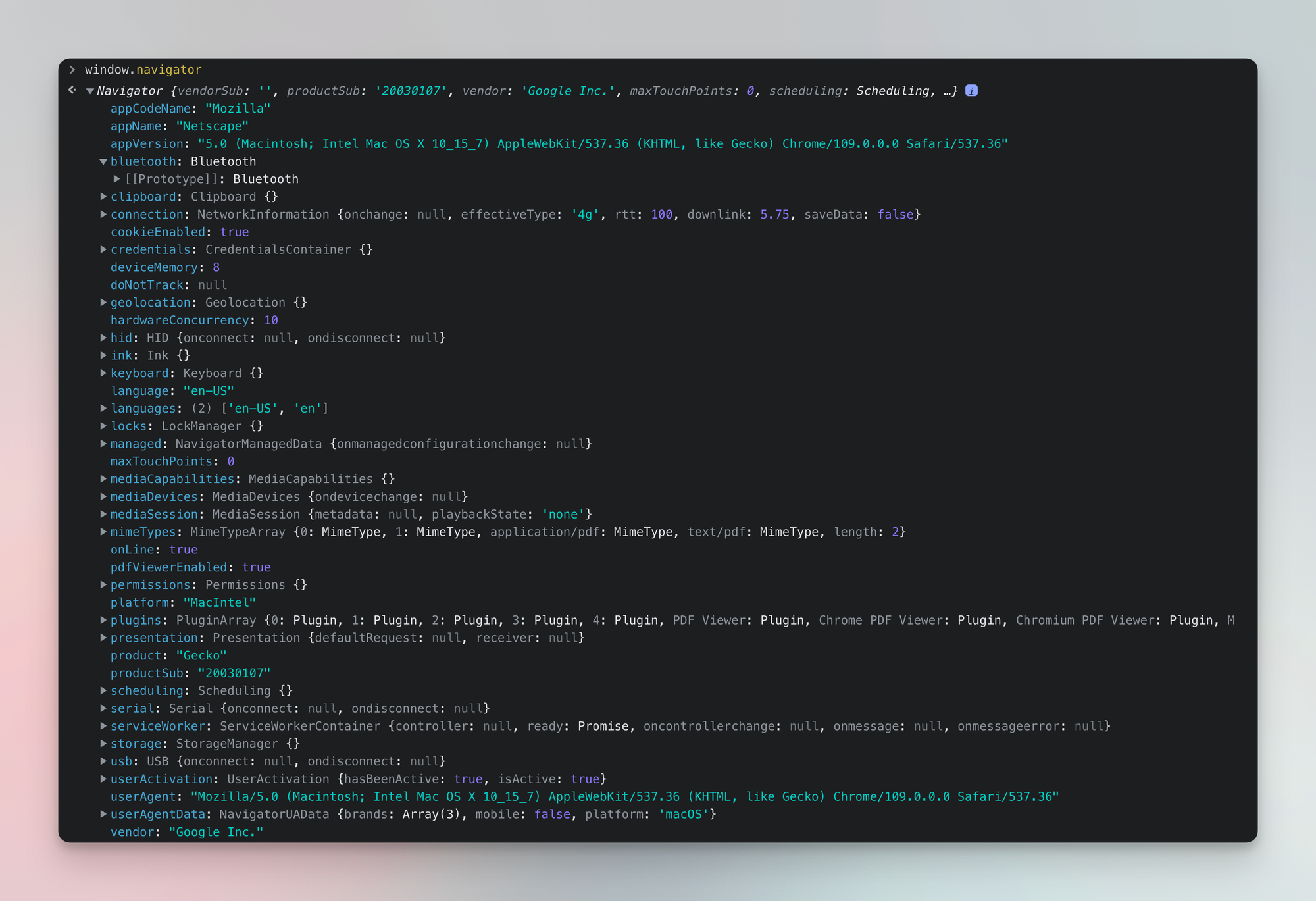
Data available about your browser via web APIs that can be used to produce a fingerprint
Although this kind of anti-scraping measure is of a higher rank, it’s useful to know how to deal with it. You’ll need to produce a unique fingerprint uniting all those parameters, and you can use the JavaScript fingerprinting suite to that end. It consists of two parts: fingerprint generator and fingerprint injector.
The generator creates a browser signature that includes an OS, device, and various browser data points like screen size, video card information, hardware features and so on; it will add the matching headers as well. The generator uses a statistical model computed from fingerprints of real devices and randomizes dynamic variables like browser viewport, to create virtually unlimited amounts of human-like fingerprints.
The injector then adds all those parameters to the browser in a hard-to-detect way. As a result, we have a browser presenting a believable, realistic fingerprint with many variables, which makes our scraper very hard to distinguish from a human user.
For instance, here’s how to create a browser fingerprint using a Playwright-managed Firefox instance:
const { firefox } = require('playwright');
const { FingerprintGenerator } = require('fingerprint-generator');
const { FingerprintInjector } = require('fingerprint-injector');
(async () => {
const fingerprintGenerator = new FingerprintGenerator();
const { fingerprint } = fingerprintGenerator.getFingerprint({
devices: ['desktop'],
browsers: [firefox],
});
const fingerprintInjector = new FingerprintInjector();
const browser = await firefox.launch({ headless: false });
// With certain properties, we need to inject the props into the context initialization
const context = await browser.newContext({
userAgent: fingerprint.userAgent,
locale: fingerprint.navigator.language,
viewport: fingerprint.screen,
});
// Attach the rest of the fingerprint
await fingerprintInjector.attachFingerprintToPlaywright(context, browserFingerprintWithHeaders);
const page = await context.newPage();
// ... your code using `page` here, with a human-like fingerprint
})();
The above-mentioned Crawlee library can make this even simpler by automating the whole generation and injection process:
import { PlaywrightCrawler } from 'crawlee';
const crawler = new PlaywrightCrawler({
browserPoolOptions: {
useFingerprints: true, // this is the default
fingerprintOptions: {
fingerprintGeneratorOptions: {
browsers: [{ name: 'edge', minVersion: 96 }],
devices: ['desktop'],
operatingSystems: ['windows'],
},
},
},
requestHandler: async ({ page }) => {
// use the human-like Playwright page
}
});
When you’re using good fingerprints and still can’t pass the website’s anti-bot checks, try to limit the fingerprint generation to the OS of the device you’re running your scraper on. Some protections are very sophisticated and will be able to detect the mismatch between the fingerprint and the hardware metrics it collected. It might sound counterintuitive, but sometimes admitting that you’re running on Linux is the best thing you can do to pass.
#3 🔥 Fight Cloudflare with headless browsers
… checking if the connection is secure… Forever stuck in Cloudflare’s waiting room… Cloudflare is a popular web application firewall known to most web users for its "waiting screen". While we are waiting to see the website, Cloudflare runs tests on visitors to determine if they are human or bots. It is important to note that not all of those tests of Cloudflare are easily detectable. But anyone who’s done web scraping knows that none of the popular HTTP clients can pass through its browser challenges on their own.
If you’ve ever attempted to scrape a website protected by Cloudflare, some of these errors might look familiar to you: Error 1020 and 1012 (Access Denied), Error 1010 (browser signature ban), Error 1015 (Rate Limited). These errors will usually be accompanied by a 403 Forbidden HTTP status code.
Cloudflare examples
For example, if we try to open a Cloudflare protected website like https://crunchyroll.com with the Got HTTP client we will receive a 403 error even if we use residential proxies:
import got from 'got';
import { HttpProxyAgent } from 'hpagent';
const response = await got('https://crunchyroll.com', {
agent: {
http: new HttpProxyAgent({
proxy: `http://country-US,groups-RESIDENTIAL:p455w0rd@proxy.apify.com:8000`
})
},
});
HTTPError: Response code 403 (Forbidden)
However, Crunchyroll does not use a super strict Cloudflare configuration, so we're able to open it with Got-Scraping, thanks to its HTTP2, TLS, and browser-like headers:
import { gotScraping } from 'got-scraping';
const response = await gotScraping({
url: 'https://crunchyroll.com/',
proxyUrl: 'http://country-US,groups-RESIDENTIAL:p455w0rd@proxy.apify.com:8000',
});
But, if a website is strict with its configuration and throws a browser-challenge immediately, not even Got Scraping can get through:
import { gotScraping } from 'got-scraping';
const response = await gotScraping({
url: 'https://putlocker.tl/',
proxyUrl: 'http://country-US,groups-RESIDENTIAL:p455w0rd@proxy.apify.com:8000',
});
<div id="challenge-body-text" class="core-msg spacer">
putlocker.tl needs to review the security of your connection before proceeding.
</div>
Putlocker is a website that streams pirated movies. We find it kinda hilarious that the strongest anti-scraping protection can be found on a website with pirated content 🏴☠️
How to avoid Cloudflare bans
The first weak point of web scrapers that Cloudflare pays particular attention to are HTTP request headers. If you don't spoof your user agent and use the default one from your HTTP library, it will most likely be labeled. For example: User-Agent: curl/7.85.0. It's easy for Cloudflare to identify it as a scraper. That's why the Got HTTP client was blocked on our first try.
Additionally, Cloudflare can also block the request if it's missing headers that a specific browser would typically send or if the included headers don't match the user-agent. For example, as mentioned above, if your user-agent is set to Safari, but the headers include the above-mentioned Sec-Fetch-Site header, Cloudflare will notice that mismatch and block your request. This is why Got Scraping was able to bypass some versions of Cloudflare, because it uses consistent headers and TLS signatures.
Still, even if you pass the HTTP header check, Cloudflare might run your client through a JavaScript challenge that checks browser consistency by inspecting available Web APIs like Navigator and generally performs quite complex fingerprinting. If you're using a simple HTTP client and can't execute JavaScript, you will fail. This is why in our last example, Got Scraping failed to open the website. If you try to execute JavaScript in a non-standard environment, you are also likely to fail. Theoretically, it's possible to build a JS engine that beats the Cloudflare challenge, but the challenge changes quite frequently, so it's not very efficient.
The most reliable solution to bypass Cloudflare is to use a headless browser with tools such as Puppeteer or Playwright. A headless browser can solve both of the problems described above for us: it renders JavaScript and eliminates the possible browser headers mismatch (because it’s literally a browser).
The easiest way to do this with Puppeteer or Playwright is by using Crawlee, because Crawlee injects human-like fingerprints into Playwright or Puppeteer, making them indistinguishable from human users.
import { Actor } from 'apify';
import { PlaywrightCrawler } from 'crawlee';
// We use Apify Proxy as an example, but you can use any proxy.
const proxyConfiguration = await Actor.createProxyConfiguration({
groups: ['RESIDENTIAL'],
countryCode: 'US',
})
const crawler = new PlaywrightCrawler({
headless: false,
sessionPoolOptions: {
// Cloudflare responds with 403 by default,
// Crawlee normally retries those codes.
// We tell it not to.
blockedStatusCodes: [],
},
proxyConfiguration,
requestHandler: async ({ page, saveSnapshot }) => {
// Naively wait for the browser challenge to complete.
await page.waitForTimeout(15000);
await page.content();
}
});
await crawler.run(['https://putlocker.tl']);
And here we go, we open Putlocker:
<div class="top"><span id="menu-mobie"><i class="fa fa-bars"></i></span>
<a href="https://www2.putlocker.tl" title="Putlocker - Watch Movies Online Free"><img
src="https://putlocker.tl/themes/movies/css/images/logo.jpg" alt="Putlocker - Watch Movies Online Free">
</a>
<form method="post" onsubmit="return do_search();">
<input type="text" id="keyword" value="Enter Movie Name..." onfocus="this.value = ''" class="form-control ">
<button onclick="return do_search();">Search Now!</button>
</form>
<span id="search-mobie"><i class="fa fa-search"></i></span>
</div>
#4 🤖 Find a way to solve CAPTCHA automatically
There’s a high chance that at some point when scraping, you’ll be challenged by Cloudflare in yet another way. Cloudflare, but also any regular website, can test you with a Captcha to see if you’re a real user.
Many websites use ReCaptcha, a tool developed by Google, to determine whether a website visitor is a real person or a bot. It is essentially a simplified version of a Turing test that only humans can solve, and if the test is completed successfully within a certain time frame, the website will consider the user to be human and let them access the website.
So if you’re either using weak or no fingerprints, or scraping a website on a large scale (meaning visiting it frequently), the website will notice this and could decide to challenge your scrape with a CAPTCHA. At some point, your scraper might lose access to the website’s content, constantly seeing the CAPTCHA page instead. If you don’t solve it, you have a high chance of getting your IP blocked.
Whether you’ll get a CAPTCHA depends on various factors, such as the website's configuration and the level of perceived risk. Sometimes the website always presents a CAPTCHA, no matter the level of suspicion your actions would get. In any case, it’s good to have a plan for solving it.
Do a bit of detective work
When encountering a CAPTCHA, instead of immediately trying to find a way to bypass it programmatically, it's important to consider why the CAPTCHA was presented in the first place. This is likely because your scraping bot has somehow revealed that it’s not a human user.
So before attempting to bypass the CAPTCHA, it's better to evaluate whether you've done everything in your power to make your scraper appear as human-like as possible. This includes all the jazz above and more: using proxies, properly setting headers and cookies, generating a custom browser fingerprint, and experimenting with different scraping methods, such as using different browsers. Once you’ve fixed the gaps in these areas, the CAPTCHA should stop bothering you.
Solve CAPTCHA automatically
If you’ve exhausted the methods mentioned in the paragraph above, you should know that there are a few CAPTCHA providers and even more CAPTCHA solvers. Historically, Cloudflare has been using reCAPTCHA as their primary CAPTCHA provider. In 2020, a lot of websites swapped Google’s reCAPTCHA v3 in favour of hCaptcha, mainly because of reCAPTCHA’s ad tracking and inability to opt out from its application across the whole website.
There are numerous services that allow you to bypass these restrictions by solving the reCaptcha automatically, and if they can't do that, they fall back to using relatively cheap human work. They're surprisingly fast at it too, so you just send an API call and receive a solved CAPTCHA in the response.
Because of these factors, it is widely acknowledged that besides being inefficient and ethically questionable, CAPTCHAs also negatively impact the user experience.
🤖 More on why CAPTCHAs are bad UX and is it legal to bypass them?
So the conclusion here is: do everything in your power not to come across a CAPTCHA, try to modify your scraper’s behavior if you do, and worst case - use an automated CAPTCHA solver to get over it.
#5 🐝 Make a script to avoid honeypot traps
This one is also more of a preventive hack. Honeypots (and honeynets) are a known measure to protect websites from all kinds of evils: spammers, DDoS attacks, and general malware. Unfortunately, that list includes web scrapers as well. Spider honeypots - as they are sometimes called - are unfortunately not built to distinguish between bad and good bots. So what’s the trap about?
Humans use websites as humans and only click on links that they can see. The websites use this to their advantage by setting up a few links that are only visible to a bot that is following the HTML code. For instance, those links might have the “display: none” CSS style or simply blend in with the background color, making them invisible to a human eye, but easily found by a bot. Another example could be hidden pagination, with the last page being fake. The point is, if the bot acts on this invisible link, the system blacklists it immediately. So how do we deal with this issue?
How do I avoid honeypot traps when web scraping?
- Do your research. This method needs only the HTTP information, so your best bet is to research this topic and find as many ways as possible to avoid the honeypot. Here’s an example of a function that detects some of the more trivial honeypot links:
function filterLinks() {
const links = Array.from(document.querySelectorAll('a[href]'));
console.log(`Found ${links.length} links on the page.`);
const validLinks = links.filter((link) => {
const linkCss = window.getComputedStyle(link);
const isDisplayed = linkCss.getPropertyValue('display') !== 'none';
const isVisible = linkCss.getPropertyValue('visibility') !== 'hidden';
if (isDisplayed && isVisible) return link;
});
console.log(`Found ${links.length - validLinks.length} honeypot links.`);
}
Don’t skip the robot.txt file. It might contain clues as to where the honeypots can be set up. If the file explicitly forbids going on some specific content-rich pages, you better watch out when scraping there. If you do end up getting caught, the website has a reason to block you since it specifically indicated not to visit that.
Be careful. You should be cautious of honeypots because getting trapped in one could have serious repercussions for your scraper. Honeypot traps are often used in conjunction with tracking systems that can identify requests by fingerprints. This means that once they connect the dots, the website will be able to recognize your requests even if they come from a different IP address, making it harder to scrape it in the future.
Conclusion
No web scraper is created blocking-proof. Even the theoretically best-built web crawler can be powerless against new anti-scraping techniques. This is why building the scraper is half the job, another is supporting it with infrastructure that sets up your crawler for success. So if you’re drowning in waves of blocking, here’s a list of questions to help you navigate:
Are you using proxies?
Are you making the request with the proper headers and user agents?
Are you generating and using a unique browser fingerprint that’s consistent with a real-world device?
Are you trying different general scraping methods (HTTP scraping, browser scraping)?
If you are using browser scraping, have you tried using a different browser?
When you're building a web scraper, it's important to double-check and tweak the settings related to things like headers and user-agents. Doing this can help you avoid getting blocked by most websites. By setting up your scraper correctly, you'll have a better chance of getting the data you need without running into any roadblocks.