

What is retrieval-augmented generation, and why use it for chatbots?
RAG is revolutionizing search and information retrieval. We explain how it works.

Hi, we're Apify, a full-stack web scraping and browser automation platform. We're already deeply involved in collecting high-quality data for AI. Check us out.
What is RAG (retrieval-augmented generation)?
If you’ve ever used LangChain, you’re probably aware that it can create chatbots and do Q&A over any website or document. You can see an example in the LangChain documentation.
How does it do this? The answer is retrieval-augmented generation, often referred to by its acronym, RAG.

RAG is an AI framework and technique used in natural language processing that combines elements of both retrieval-based and generation-based approaches to enhance the quality and relevance of generated text. It first came to the attention of AI developers in 2020 with the publication of the research paper, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Since then, it has come to be used as a way to improve generative AI systems.
How does retrieval-augmented generation work?
The RAG process sounds deceptively simple: it supplements a user’s input to a large language model like ChatGPT with additional data retrieved from elsewhere. The LLM can then use that data to augment the generated response.
In other words, RAG systems are a fusion of information retrieval and text generation. They make use of pre-existing knowledge sources, such as large text corpora or databases, to retrieve pertinent information and then generate coherent and contextually appropriate text based on that retrieved content.
Let's break it down, shall we?
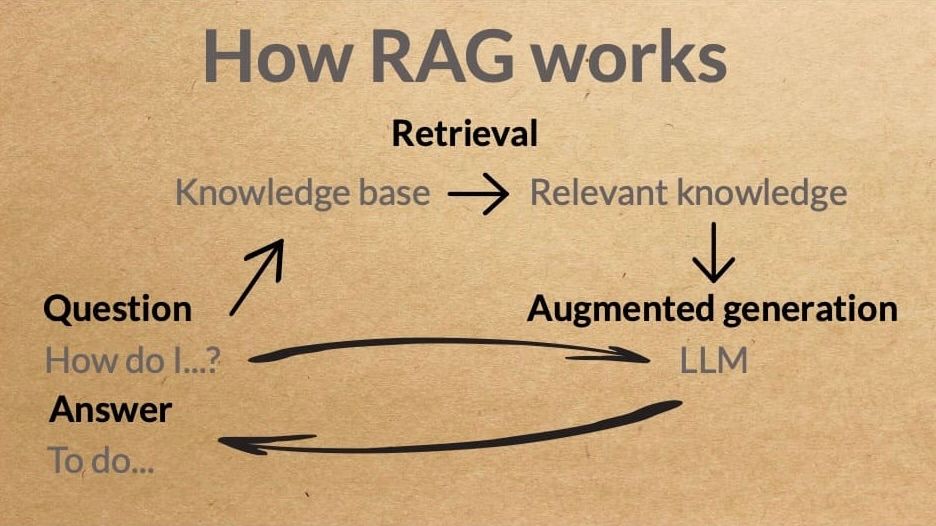
How do RAG chatbots work?
1. The retrieval-based component
RAG chatbots have a retrieval-based component (not to be confused with fine-tuning) that stores and retrieves pre-defined responses from a database or knowledge base. These responses are typically short and specific to common user queries. Retrieval-based models use techniques like TF-IDF (Term Frequency-Inverse Document Frequency) or neural network-based embeddings stored in a vector database to find the most relevant response.
2. The generative component
In addition to the retrieval-based component, RAG chatbots have a generative component that can generate responses from scratch. Generative models, such as transformer-based models like ChatGPT, are used for this purpose. They can generate more diverse and contextually relevant responses but may be less reliable than retrieval-based responses.
3. Retrieval-augmentation
The key innovation in RAG chatbots is the retrieval-augmentation step. Instead of relying solely on generative responses or retrieval responses, RAG models combine both. When a user query is received, the model first retrieves a set of candidate responses from the retrieval-based component. Then, it uses the generative component to refine or enhance the retrieved response.

Why use retrieval-augmented generation for chatbots?
The reason RAG is a popular method for creating chatbots is that it combines retrieval-based and generative-based models. Retrieval-based models search a database for the most relevant answer. Generative models create answers on the fly. The combination of these two capabilities is what makes RAG chatbots both efficient and versatile. Which brings us to…
What are the benefits of retrieval-augmented generation?
1. It mitigates hallucinations
Because it incorporates retrieved information into the response generation process, RAG helps reduce the likelihood of the model making things up or generating incorrect information. Instead, it relies on factual data from the retrieval source.
2. It's more adaptable
RAG systems can handle a wide range of user queries, including those for which no pre-defined response exists, thanks to their generative component. Moreover, the retrieval mechanism can be fine-tuned or adapted to specific domains or tasks, which makes RAG models versatile and applicable to a wide range of NLP applications.
3. It produces more natural language
RAG models can produce more natural-sounding responses compared to purely retrieval-based models. Furthermore, they can personalize generated content based on specific user queries or preferences. By retrieving relevant information, the models can tailor the generated text to individual needs.
How to collect data for RAG chatbots
To create or enhance a retrieval-augmented generation chatbot or any other RAG system, you need data for your knowledge base or database, so let's end with where to begin. Here's a step-by-step process for collecting data for RAG chatbots.

1. Creating a knowledge base
Start by collecting and organizing structured data that will serve as your knowledge base. Data for the knowledge base can be collected through manual curation, data entry, or data extraction from online sources. The data can be facts, FAQs, product information, or any other relevant data. Ensure that it's well-structured and tagged with categories and keywords.
2. Web scraping
Data extraction, aka web scraping, is often used to expand the knowledge base and keep it updated with the latest information from the web. Web scraping techniques involve using software tools or scripts to access web pages, parse the HTML content, and retrieve specific information.
If you want to collect data specifically for ChatGPT and LLMs, there's a range of extractors and integrations for AI available for your needs.
3. Data cleaning
Clean and preprocess the scraped data to remove noise, duplicates, or irrelevant information. We recommend using Website Content Crawler, which has built-in HTTP processing and data-cleaning functionalities.
This tutorial on collecting data for LLMs shows you how to use Website Content Crawler to crawl, scrape, clean, and process data for AI models.
4. Training data for the generative component
If your chatbot includes a generative component, you'll need training data for fine-tuning the model (using RAG and fine-tuning in tandem is the ideal solution). This data may consist of conversational or text data relevant to your application domain. You'll need to ensure that the data is appropriately labeled for training.
5. Integration
Finally, integrate the knowledge base and training data into your RAG chatbot architecture, allowing the model to retrieve and generate responses based on user queries.
FAQs
How does RAG differ from traditional chatbots?
Unlike traditional chatbots that rely solely on pre-programmed responses or generative models, RAG chatbots use a combination of retrieval-based responses (from a knowledge base) and generative responses (created dynamically). This allows for more adaptive and context-aware conversations.
What are the key components of a RAG chatbot?
A RAG chatbot typically comprises three key components: a retrieval-based component (knowledge base), a generative component (usually based on models like GPT-4), and a retrieval-augmentation mechanism that combines both for generating responses.
How does the generative component enhance RAG chatbots?
The generative component of RAG allows the chatbot to generate responses that are contextually relevant and tailored to the user's query, even when there's no pre-defined answer in the knowledge base. It adds flexibility and adaptability to the system.
Why is retrieval-based knowledge important in RAG?
Retrieval-based knowledge provides a foundation of accurate and specific information. It ensures that the chatbot can answer common queries effectively, improving response quality and reliability.
What's the difference between fine-tuning and retrieval?
Fine-tuning is a method used to adapt a pre-trained model to perform specific NLP tasks by training it further on task-specific data. It involves updating the weights of an LLM pre-trained on a dataset. Retrieval involves selecting or retrieving pre-existing responses from a knowledge base based on the input.
Is RAG the same as generative AI?
No. Generative AI is a subfield of AI focused on creating systems capable of generating new content, such as images, text, music, or video. Retrieval-augmented generation is a technique that uses knowledge external to data already contained in the LLM to provide better results to queries.
How does generative AI use RAG?
Data from data sources is embedded into a knowledge repository and then converted to vectors, which are stored in a vector database. When an end user makes a query, the vector database retrieves relevant information. This information is sent along with the query to the LLM, which uses the context to create a more contextual response.
What type of data is used in retrieval-augmented generation?
RAG can incorporate data from relational databases, unstructured document repositories, internet data streams, media newsfeeds, audio transcripts, and transaction logs.
Can a RAG system cite references for the data it retrieves?
The vector databases and indexes used by retrieval-augmented generation contain specific data about the sources of information. So yes, sources can be cited, and errors in those sources can be corrected or deleted so that subsequent queries won’t return the same incorrect information.
Can RAG chatbots understand context in a conversation?
Yes, RAG chatbots are designed to understand and maintain context within a conversation. They can remember and refer back to previous user queries and responses, ensuring a coherent and context-aware interaction.
In what applications can RAG chatbots be useful?
RAG chatbots find applications in customer support, content recommendation, virtual assistants, medical diagnosis, and any domain where providing accurate and contextually relevant information is crucial.
What are the benefits of using RAG in conversational AI?
The benefits of RAG include improved response relevance, adaptability to a wide range of user queries, natural-sounding conversation, better user engagement, and the ability to provide both pre-defined and dynamically generated responses.
What are some challenges in implementing RAG chatbots?
Challenges include maintaining the accuracy and relevance of the knowledge base, ensuring a balance between retrieval and generation for optimal responses, handling out-of-scope queries, and addressing ethical concerns related to data sources and model behavior.
How is data collected for the knowledge base in RAG chatbots?
Data for the knowledge base can be collected through manual curation, data entry, or web scraping. Also known as data scraping, data extraction, or data harvesting, web scraping is commonly used to keep the knowledge base updated with the latest information from the web.
Can AI do web scraping?
It's possible to combine AI algorithms with web scraping processes to automate some data extraction activities, such as transforming pages to JSON arrays. AI web scraping is more resilient to page changes than regular scraping as it doesn’t use CSS selectors. However, AI models are restricted by limited context memory.




